# Adan Condori — Full Content Corpus
> Source: https://adancondori.github.io/. Senior Engineering Leader, 10+ years building payment systems. This file concatenates the full markdown content of every blog post for AI engines that prefer single-file ingestion. Generated on 2026-06-21.
---
================================================================================
## Post: 2019-12-05-android-vs-kotlin
Source file: _posts/2019-12-05-android-vs-kotlin.md
================================================================================
---
layout: post
title: "Kotlin vs Java - Spanish"
modified:
categories:
excerpt: >
Entonces, estas son las razones por las que mudarse a Kotlin es una de las mejores cosas que puede hacer.
tags: []
image:
feature:
date: 2019-12-05T19:23:53-07:00
---
## **Kotlin vs Java**
En mis 7 años desarrollando Android Java sigue siendo estandar para el desarrollo de aplicaciones nativas, pero no quiero decir que sea mejor o bueno, recordemos que Kotlin es un idioma con soporte oficial para escribir aplicaciones de Android, asi mismo kotlin en los últimos años a ganado bastante popularidad, a continuación listo algunas razones porque mudarse a kotlin.
- El lenguaje y el entorno están maduros
- Está perfectamente integrado con Android Studio
- Su evolución está bien cubierta
- Es mucho más seguro que Java
- Kotlin es multi-plataforma
Entonces, estas son las razones por las que mudarse a Kotlin es una de las mejores cosas que puede hacer.
| **Parámetro** | **Java** | **Kotlin** |
| ------------------ | --------- | --------------- |
| Compilacion | Bytecodes | Máquina virtual |
| Seguridad nula | Χ | √ |
| Expresión Lambda | Χ | √ |
| Matriz invariante | Χ | √ |
| Campos no privados | √ | Χ |
| Casts inteligentes | Χ | √ |
| Miembros estáticos | √ | Χ |
| Tipos de comodines | √ | Χ |
| Objetos Singletons | √ | √ |
================================================================================
## Post: 2020-10-15-desing-patterns
Source file: _posts/2020-10-15-desing-patterns.md
================================================================================
---
layout: post
title: "Desing Patterns - Spanish"
modified:
categories:
excerpt: >
Son técnicas de desarrollo aplicables bajo el paradigma orientado a objetos que tienen como objetivo principal dar una solución genérica a problemáticas tipicas y recurrentes que se presentan en la etapa de diseño en cualquier metodología de desarrollo de software.
tags: []
image:
feature:
date: 2020-10-15T23:23:53-07:00
---
## Patrones de Diseño (Desing Patern)
Soy un programdor y muchas siempre escuche hablar de patrones de diseño. Y de seguro que has manejado o conoces algunos patrones como el conocido Singleton. Los patrones de diseño son muy útiles al momento de hacer software, por lo cual cada programados deberia conocer por lo menos los patrones mas conocidos de esta manera evitaremos dolores de cabeza.
Bueno a acontinuación explicare la importancia del uso de estos patrones en un software.
### ¿Qué son los patrones de diseño?
Son técnicas de desarrollo aplicables bajo el paradigma orientado a objetos que tienen como objetivo principal dar una solución genérica a problemáticas tipicas y recurrentes que se presentan en la etapa de diseño en cualquier metodología de desarrollo de software.
### ¿Por qué usar patrones de diseño?
Como ya vimos en el artículo sobre [principios de diseño](https://www.genbetadev.com/metodologias-de-programacion/doce-principios-de-diseno-que-todo-desarrollador-deberia-conocer), si queremos desarrollar aplicaciones robustas y fáciles de mantener, debemos cumplir ciertas "reglas". Lo pongo entre comillas porque aunque estas reglas de diseño son recomendables (muy recomendables), no son obligatorias. Siempre podemos decidir no aplicarlas. Aunque si no lo hacemos, hay que ser conscientes de la razón de no aplicarlas y de sus consecuencias.
**Los patrones de diseño nos ayudan a cumplir muchos de estos principios o reglas de diseño**. Programación [SOLID](https://www.genbetadev.com/paradigmas-de-programacion/solid-cinco-principios-basicos-de-diseno-de-clases), control de cohesión y acoplamiento o reutilización de código son algunos de los beneficios que podemos conseguir al utilizar patrones.
================================================================================
## Post: 2020-10-20-software-design
Source file: _posts/2020-10-20-software-design.md
================================================================================
---
layout: post
title: "¿What is Software Design? - Spanish"
modified:
categories:
excerpt: >
La ingenieria de softtware es un conjunto de procesos en la cual se define test unitarios, arquitectura, componentes, interfaces y entre otras características con el objetivo de obtener la solución requerida.
tags: []
image:
feature:
date: 2020-10-20T23:23:53-07:00
---
### ¿Qué es Diseño de de Software?
La ingenieria de softtware es un conjunto de procesos en la cual se define test unitarios, arquitectura, componentes, interfaces y entre otras características con el objetivo de obtener la solución requerida.
Asi mismo el diseño de software viene desde la sexta generación de computadoras 1900 en adelante, tal vez en ese entonces nos se conocia el termino Diseño de Software, pero si se ultilizaban los mismos pasos que se utilizan en la actualidad como la captura de requisitos, arquitectura, diseño de interfaces etc., pero en los ultimos 10 años, al diseño de software le ha acompañado las metodologias de desarrollo como Lean, Scrum con el objetivo de mejorar proceso de desarrollo asi mismo el diseño de software.
Algunas procesos del diseño de software han hido perfeccionando a lo largo del tiempo como las formas de realizar capturas de requisitos, nuevas arquitecturas de software, la automatización de pruebas, tambien la documentacion se ha mejorando, disminuyendo y adaptandose a la necesitad real del Software.
Desde nuestro punto de vista el Desarrollo de software mantiene los siguientes pasos, captura de requisitos, análisis, Diseño del software, implementación y pruebas, tomando como factor importanto el Diseño de Software ya que este puntos sera el que defina si el sistemas sera robusto y algo pequeño, ya que en el Diseño de Software se define la Arquitectura del software, interfaces, tecnologías, si se aplicaran patrones de diseño etc. El tiempo de Diseño de Software deberia ser la mitad del tiempo estimado tomando en cuenta los siguientes puntos segun Davis:
- **El diseño tendría que ser rastreable por el modelo de análisis.**
- **El diseño no tendría que reinventar la rueda.**
- **El diseño debe "minimizar la distancia intelectual" entre el software y el problema tal y como existe en el mundo real.**
- **El diseño tiene que exhibir uniformidad e integración.**
- **El diseño tendría que ser estructurado para adaptarse al cambio.**
- **El diseño tendría que estar estructurado para degradarse suavemente, incluso cuándo los datos, los acontecimientos o las condiciones operativas son irregulares.**
- **El diseño no es codificación, la codificación no es diseño.**
- **La calidad del diseño tendría que ser evaluado cuando se está creando, no después.**
- **El diseño tendría que ser revisado para minimizar los errores conceptuales (semánticos)**.
### Conclución:
El Diseño de Software es muy importante en el desarrollo de software ya que esta definira la estabilidad, el rendimiento, los nuevos cambios que se necesiten. Por lo cual se debe tomarse un buen tiempo de análisis para definir el Diseño del Software.
### Referencias:
https://es.wikipedia.org/wiki/Dise%C3%B1o_de_software
https://sesitdigital.com/tendencias-de-desarrollo-de-software-para-el-2020/
https://www.monografias.com/trabajos73/diseno-software/diseno-software.shtml
================================================================================
## Post: 2020-10-21-notes-git
Source file: _posts/2020-10-21-notes-git.md
================================================================================
---
layout: post
title: "Notes Git - Spanish"
modified:
categories:
excerpt: >
Mis notas sobre el curso y mi experiencia con Git y gitHub
tags: []
image:
feature:
date: 2021-04-29T08:23:53-07:00
---
# Notes Git (Spanish)
## Configuración de Git
**Primer paso: Generar tus llaves SSH**. Recuerda que es muy buena idea proteger tu llave privada con una contraseña.
```bash
ssh-keygen -t rsa -b 4096 -C "youremail@example.com"
```
**Segundo paso**: Terminar de configurar nuestro sistema.
**En Windows y Linux**:
```bash
# Encender el "servidor" de llaves SSH de tu computadora:
eval $(ssh-agent -s)
# Añadir tu llave SSH a este "servidor":
ssh-add ruta-donde-guardaste-tu-llave-privada
```
**En Mac**:
```bash
# Encender el "servidor" de llaves SSH de tu computadora:
eval "$(ssh-agent -s)"
# Si usas una versión de OSX superior a Mac Sierra (v10.12)
# debes crear o modificar un archivo "config" en la carpeta
# de tu usuario con el siguiente contenido (ten cuidado con
# las mayúsculas):
Host *
IPQoS=throughput ## this line is optional in diferents version on mac
AddKeysToAgent yes
UseKeychain yes
IdentityFile ruta-donde-guardaste-tu-llave-privada
# Añadir tu llave SSH al "servidor" de llaves SSH de tu
# computadora (en caso de error puedes ejecutar este
# mismo comando pero sin el argumento -K):
ssh-add -K ruta-donde-guardaste-tu-llave-privada
```
## Ejemplo
Usando git
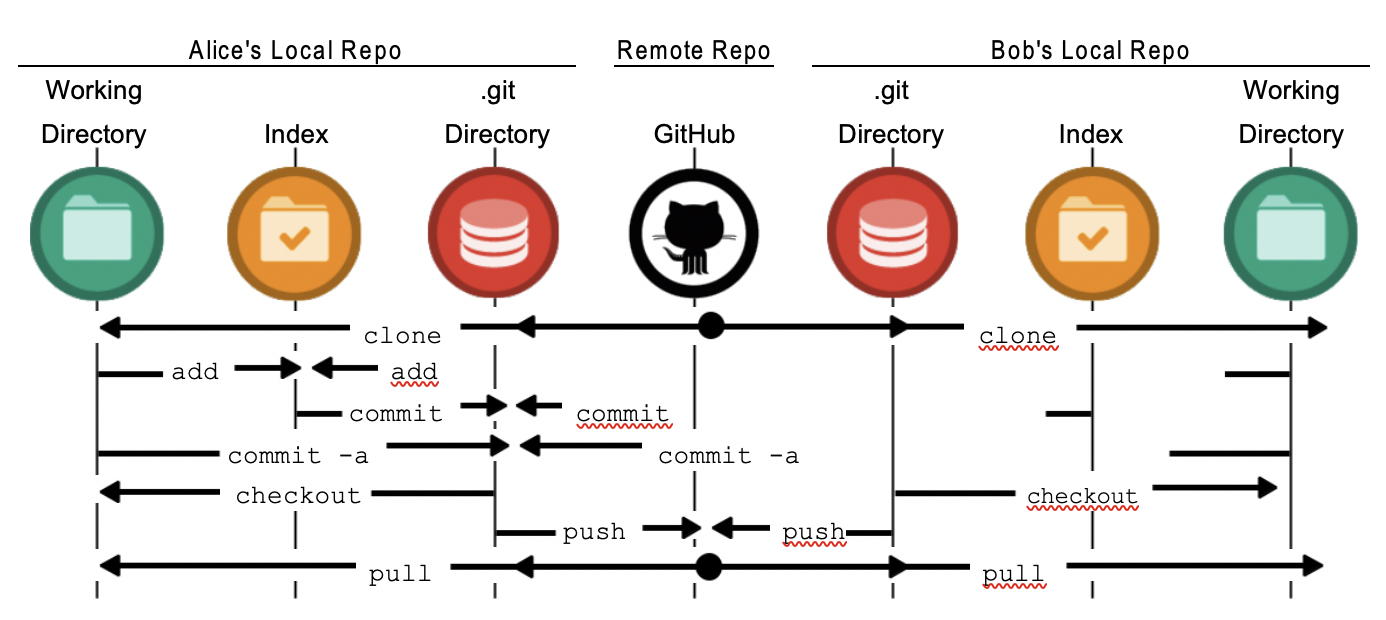
## Comandos de ayuda
Como volver atrás después de hacer un **git add .**
```sh
git add . // or git add name_file
```
luego borramos los cambios desde el staging
```sh
git rm name_file
git rm --cached name_file
```
Como comparar el historial de un archivo modificado
```sh
git log
git diff hash1 hash2
```
Como volver commit anterior
```bash
git reset hash --hard
```
Mostrar todos los log y diferencias
```bash
git log --stat
```
Crear alias para mostrar gráfico en consola
```bash
arbolito="git log --all --graph --decorate --oneline"
```
## Manejo de Tags
```bash
# Creación de tagg
git tag -a nametag -m "mensaje personalizado referente del tag" hashcommit
# Sube todos los tags creados
git push origin --tags
# Borra Tags locales
git tag -d nametag
# Borrar Tags de los repositorios remotos
git push origin :refs/tags/tagName
```
Delete Tag
```bash
git tag -d
```
## Buscar palabras en archivos y commit
- **`git grep color`** --> use la palabra color
- **`git grep la`** --> donde use la palabra la
- **`git grep -n color`** –> en que lineas use la palabra color
- **`git grep -n platzi`** --> en que lineas use la palabra platzi
- **`git grep -c la`** --> cuantas veces use la palabra la
- **`git grep -c paltzi`** --> cuantas veces use la palabra platzi
- **`git grep -c “”`** –> cuantas veces use la etiqueta
- **`git log-S “cabecera”`** --> cuantas veces use la palabra cabecera en
todos los commits.
- **`grep`** –> para los archivos`
- **`log`** -> para los commits.
## Comandos colaborativos
- **`git shortlog`**: Ver cuantos commits a hecho los miembros del equipo
- **`git shortlog -sn`**: Las personas que han hecho ciertos commits
- **`git shortlog -sn --all`**: Todos los commits (también los borrados)
- **`git shortlog -sn --all --no-merges`**: muestra las estadisticas de los comigs del repositorio donde estoy
- **`git config --global alias.stats “shortlog -sn --all --no-merges”`**: configura el comando “shortlog -sn --all --no-merges” en un Alias en las configuraciones globales de git del pc
- **`git blame -c blogpost.html`**: Muestra quien ha hecho cambios en dicho archivo identado
- **`git blame --help`**: Muestra en el navegador el uso del comando
- **`git blame archivo -L 35, 60 -c`**: Muestra quien escribio el codigo con informacion de la linea 35 a la 60, EJ: `git blame css/estilos.css -L 35, 60 -c`
- **`git branch -r`**: Muestra las Ramas remotas de GitHub
- **`git branch -a`**: Muestra todas las Ramas del repo y remotas de GitHub
## Estados del archivos
Untracked -> staging -> repository local -> remote
## Migrar repositorio
Mover contenido de repositorio Git a otro repositorio conservando el Historia
```sh
git clone
cd go-directore
git branch -a // To see a list of the different branches
git branch -r | grep -v '\->' | while read remote; do git branch --track "${remote#origin/}" "$remote"; done
git fetch --all
git pull --all
git remote rm origin
git remote add origin
git push origin --all
git push --tags
```
## Creacion de Alias
Creando alias:
```sh
git confing --global alias. ''
```
Por ejemplo:
```sh
git config --global alias.lod 'log --oneline --decorate --color'
git config --global alias.lodag 'log --oneline --decorate --all --graph'
```
Listar alias:
```sh
git config --global --get-regexp alias
```
Eliminar un alias:
```sh
git config --global --unset alias.
```
Por ejemplo:
```sh
git config --global --unset alias.lodag
```
## More Command
1. **git log --oneline** ->Te muestra el id commit y el título del commit.
2. **git log --decorate** -> Te muestra donde se encuentra el head point en el log.
3. **git log --stat** -> Explica el número de líneas que se cambiaron brevemente.
4. **git log -p** -> Explica el número de líneas que se cambiaron y te muestra que se cambió en el contenido.
5. **git shortlog** -> Indica que commits ha realizado un usuario, mostrando el usuario y el titulo de sus commits.
6. **git log --graph --oneline --decorate**
7. **git log --pretty=format:"%cn hizo un commit %h el dia %cd"** - Muestra mensajes personalizados de los commits.
8. **git log -3** -> Limitamos el número de commits.
9. **git log --after=“2018-1-2”**
10. **git log --after=“today”**
11. **git log --after=“2018-1-2” --before=“today”** -> Commits para localizar por fechas.
12. **git log --author=“Name Author”** - Commits realizados por autor que cumplan exactamente con el nombre.
13. **git log --grep=“INVIE”** - Busca los commits que cumplan tal cual está escrito entre las comillas.
14. **git log – index.html** -> Busca los commits en un archivo en específico.
15. **git log -S “Por contenido”** -> Buscar los commits con el contenido dentro del archivo.
16. **git log > log.txt** -> guardar los logs en un archivo txt
## Referencias
- https://platzi.com/clases/git-github/
- https://ndpsoftware.com/git-cheatsheet.html#loc=remote_repo
================================================================================
## Post: 2021-07-06-Architecture-representation
Source file: _posts/2021-07-06-Architecture-representation.md
================================================================================
---
layout: post
title: "Representación de Arquitectura de Software"
modified:
categories:
excerpt: >
Mis notas sobre Representación de Arquitectura de Software
tags: []
image:
feature:
date: 2021-07-06T08:23:53-07:00
---
## Representación de Arquitectura de Software
## Resumen
Cuando nosotros diseñamos una Arquitectura de Software necesitamos representarla en documentos de tal manera que podamos describir y comunicar a nuestro clientes, equipo de desarrollo, dueños de productos etc., con el objetivo de trasmitir de forma sencilla, clara todas las tecnologías, componentes que estaremos utilizando en el diseño de Software.
En este articulo tratare de mostrar algunos enfoques para la documentación del diseño de arquitectura, estos enfoques me han servido en mi experiencia laboral y las he utilizado con algunos cliente que he llegado a tener. Así mismo tratare de mencionar algunas recomendaciones y ventajas sobre representaciones de Software. Este articulo no lo hago para que tu lo utilices al pie de la letra sino para que puedan conocer los enfoques que he manejado y estoy aprendiendo, por lo tanto tu puedes decidir la herramienta y el enfoque que mas se adecue a tu proyecto.
## Contexto
Actualmente tenemos varias notaciones y herramientas para representar y modelar el diseño de una Arquitectura de Software. Pero cuando estamos realizando un proyecto para una empresa consolidada o que tenga un departamento de desarrollo, nos solicitaran una documentación sobre la representación de nuestra arquitectura, por lo cual nosotros tenemos que elegir la representación que mas se adecue a nuestro proyecto, también debo mencionar que algunas empresas no piden ninguna representación de la arquitectura ó la documentación del software, solo les importa que software funcione.
## Cuerpo
Bueno cuando nosotros empezamos a diseñar debemos elegir el enfoque de documentación que tengan todas las características que necesitamos para representar nuestro proyecto. Entre las representaciones de diseño de arquitectura tenemos los siguientes:
- Modelo C4: El modelo C4 se creó como una forma de ayudar a los equipos de desarrollo de software a describir y comunicar la arquitectura de software, tanto durante las sesiones de diseño iniciales como al documentar retrospectivamente una base de código existente. [Model C4](https://c4model.com/)
- ADR: Cada proyecto de software incluye un conjunto de decisiones de arquitectura que definen límites y restricciones para un mayor diseño e implementación. Es importante documentar esas decisiones de alguna manera o, de lo contrario, es posible que un equipo de desarrollo no sepa qué decisiones se tomaron y con qué suposiciones. [Managing Architecture Decision Records with ADR-Tools](https://www.hascode.com/2018/05/managing-architecture-decision-records-with-adr-tools/), [Documenting Architecture Decisions](https://cognitect.com/blog/2011/11/15/documenting-architecture-decisions)
- ARC42: Es una opilación de experiencia practica de muchos sistemas en varios dominios, desde sistemas de información y web, en tiempo real e integrados hasta inteligencia empresarial y almacenes de datos, proporciona una plantilla para la [**documentación y comunicación**](https://www.notion.so/Arc42-Notion-Template-b3662172ccec40e69a9c3d64ef2c6223) y admite **tecnologías y herramientas arbitrarias**. [ARC42](https://arc42.org/)
- Modelo de Vistas de Arquitectura: También llamado **4+1**, es un modelo diseñado por Philippe Kruchten para describir la arquitectura de sistemas software, basados en el uso de múltiples vistas concurrentes. [Modelo de Vistas de Arquitectura 4+1](https://es.wikipedia.org/wiki/Modelo_de_Vistas_de_Arquitectura_4%2B1)
- Y Notaciones de UML: El lenguaje de modelado unificado ayuda a especificar, visualizar y documentar modelos de sistemas de software, incluida su estructura y diseño, de una manera que cumpla con todos estos requisitos [UML](https://www.uml.org/what-is-uml.htm)
Cada una de los representaciones anteriores mencionadas tienen sus fortalezas y debilidades por lo cual nosotros deberemos elegir con todo el equipo de desarrollo.
En mi opinión una de las representación mas utilizada es el Modelo C4 el cual tiene como objetivo describir nuestra arquitectura desde un nivel bajo hasta un nivel alto, es decir desde un nivel de clases y componentes hasta un nivel de arquitectura el cual podra ser entendido por nuestros clientes y el equipo de desarrollo de software.
A continuación responderemos las siguientes preguntas:
### ¿Qué criterios debemos utilizar para definir dicho método de representación como bueno?
Todos los criterios dependerán del tamaño de Proyecto que estemos realizando, pero los criterios mas comunes que deberíamos utilizar son los siguientes:
- **Cambios en el tiempo:** la representación que utilicemos debería adecuarse a posibles cambios que exista en el proyecto o en la arquitectura de software, es decir nuevos requerimientos de funcionalidades o nuevas tecnologías.
- **La documentación no debe se pesada:** La representación de arquitectura de contener la documentación necesaria y no así demasiados diagramas porque luego se vuelven inservibles y no se llegan a utilizar.
- **La documentación debe representar al código:**
- **Niveles de Abstracción:** La representación que se elija debe contener todas las notaciones básicas para demostrar los niveles de abstracción del diseño de nuestra arquitectura como por ejemplo:
1. **Forma:** Es aquella que representa los componentes y estructura del software como patrones de diseño por ejemplo: API, Monolitics Web, MVC, MVP etc. En este punto podremos identificar que es el sistema y contiene el sistema.
2. **Comportamiento:** Describe el comportamiento, funcionalidades del sistema las cuales son representadas por diagramas como Casos de Uso.
3. **Operaciones:** Describe la infraestructura que utiliza el sistema, es importante que podamos identificar para ver cómo organizar y que tecnologías se utilizaran por ejemplo: Multi-tenant despliegue, Micro-services, Load-Balances service etc.
### ¿Qué ventajas aporta el método de representación a los habitantes del sistema?
Los habitantes del sistemas son todos aquellas personas que interactúan con el software, por los cual si se elige una representación donde nuestros habitantes lleguen a entender y comprender sera fácil hacer cambios al sistemas como también se tendrá claro el alcance que puede tener nuestro software.
### ¿Qué recomendaciones de mejora tiene sobre el método de representación?
Mi recomendación es apegarse a la representación que se llegue a elegir ocupando todas sus notaciones y herramientas que nos provee, porque si solo seguimos a medio nuestra representación fracasara y el sistemas no podrá ser comprendida por ningún integrante del equipo.
## Conclusión
Existen diferentes tipos de representación para el diseño de Arquitectura de software, por lo cual es importante utilizar alguna de ellas para extender la vida de nuestro software, ademas de tener un panorama amplio de las formas, comportamientos y como sera el despliegue de nuestro sistema.
En este articulo he presentado mis investigaciones he ideas sobre las representaciones de una arquitectura de software. Cada una de estas características merece una discusión más larga y también hay otras características que no se mencionado.
================================================================================
## Post: 2021-10-20-Linux-basic
Source file: _posts/2021-10-20-Linux-basic.md
================================================================================
---
layout: post
title: "Notes Linux"
modified:
categories:
excerpt: >
Mis notas sobre el curso y mi experiencia con Linux
tags: []
image:
feature:
date: 2021-04-29T08:23:53-07:00
---
# Notes Linux Command (Spanish) - Building.....
## Directorio base de Linux
**Primer paso: Generar tus llaves SSH**. Recuerda que es muy buena idea proteger tu llave privada con una contraseña.
~~~gfm
```mermaid
stateDiagram
[*] --> Still
Still --> [*]
Still --> Moving
Moving --> Still
Moving --> Crash
Crash --> [*]
```
~~~
## Comands
Listar archivos:
```bash
ls
ls -lS
ls -lr
ls namedirectory
```
Listar archivos para ver su peso de una manera mas mas legible
```bash
ls -lh
```
Listar archivos ocultos:
```bash
ls -a
```
Identificar la ruta en la que estamos en nuestro sistema: **P**rint **W**orking **D**irectory
```bash
pwd
```
Movernos entre directorios:
```bash
cd
```
Crear un directorio:
```
mkdir namedirectory
```
Copiar un archivo:
```bash
cp
```
Borrar un archivo:
```bash
rm
rm -i myfile // interactive directory
rm -ir directory // delete all child directory
```
Mover un archivo: or you can use to rename
```bash
mv
mv filename filename2
```
Borrar un directorio:
```bash
rmdir
```
Limpiar la terminal
```bash
clear
```
Crear archivo
```bash
touch namefile
```
Show detail content by default is 10
```bash
head file
head file 10 // show 10 lines
```
Show detail content by default is 10
```bash
tail file
tail -f file // shoe file current changes
```
Less edit text
```bash
less file // you be able to use / to search
```
open file
```
xdg-open file
open file
```
Type file
```bash
type ls
```
Create Alisa
```bash
alias lista_larga = "ls -lSh"
```
Man
```bash
man
```
Wildcards: sirve para buscar archivos de extensión o nombres
```bash
ls nameext*
ls nameext?
ls *.html
ls [:alnum:]
ls -d [:upper:]
```
Wildcards
```bash
ls dirTest1 > misDirTest1.txt // create new file with all result
ls downloads >> misDirTest1.txt // create and concat file with all result
ls f2q3fdfsd 2> error.txt
```
Aditional
```bash
cowsay "Hola mundo" | lolcat
```
### Encadenando comandos: operadores de control
```bash
comand1 && comand2 // comando1 depend of comand2, only excete is command1 es success
```
Comandos or
```bash
comand1 || comand2 // comando1 NOT depend of comand2
```
- **Comandos separados por punto y coma “;” :** Se ejecutan uno seguido del otro en el orden en que fueron puesto. Uno no se ejecuta hasta que el otro proceso aya terminado.
- **Comandos separados por & :** Se ejecutan todos al mismo tiempo, es decir de forma asíncrona.
- **Comandos separados por && :** Se ejecutan solo si el comando anterior se aya ejecutado exitosamente. Suponemos que A, B y C son comando:
A && B && C
El B solo se va ejecutar si el A se ejecuta exitosamente, y el C solo se va ejecutar si el B si ejecuta exitosamente. Si el B no se ejecuta exitosamenta el C no se ejecuta. Si el A no se ejecuta exitomante el B y el C no se ejecutan.
- **Comandos separados por || :** Solo se ejecuta uno. Sea cuantos comandos tienes separados por || solo ejecuta o toma en cuenta el primer que se ejecuta exitosamente (bajo la redundacia), y descarta automaticamente los demas. Cuando uno de los comandos se ejecuta exitosamente, descarta los demas comandos.
## Referencias
- https://platzi.com/clases/git-github/
- https://ndpsoftware.com/git-cheatsheet.html#loc=remote_repo
================================================================================
## Post: 2021-14-06-Success-Skills-for-Architects-English
Source file: _posts/2021-14-06-Success-Skills-for-Architects-English.md
================================================================================
---
layout: post
title: "Summary About: \n Success Skills for Architects with Neil Ford - English"
modified:
categories:
excerpt: >
Mis notas acerca de buena arquitectura
tags: []
image:
feature:
date: 2021-06-15T08:08:53-07:00
---
This article was extracted from [Potcast Episode 287 for Neil Ford](http://www.se-radio.net/2017/04/se-radio-episode-287-success-skills-for-architects-with-neil-ford/).
## Summary
In this Postcast we will find several tips on skills and strategies to be a good software architect, then I will present a summary of this podcast which is very interesting about the experience of Neil Ford.
All people involved with software development get to make decisions in it, but the architect is the one who must have extensive knowledge about the technologies, technical skills and also have soft skills to communicate with users, managers and the development team. Architects must be in constant training with other architects to acquire knowledge, also the architect must be a leader in their environment, then let's see some characteristics of a good software architect:
- Have vision in the defined architecture decisions.
- Understand and know technologies, and multiple ways to implement the architecture.
- Have soft skills.
- Possess knowledge in terms of security, scalability, reliability, maintainability, etc.
Therefore an architect must have several skills and knowledge so he should never stop training, among the skills with the development team the architect should promote pair programming, define a representation on the architecture used which will serve the team and users, such as the C4 Model which is a representation by levels very easy to apply and very useful. It is also recommended to have all technical decisions recorded for future decisions.
When developing software it is important to make good decisions about the things we use because all this could lead to the failure or success of the software, these decisions are important to share with the whole team and especially with the new ones. Each component of the software is important so you should spend considerable time in the coding of these components, accompanied by good practices in the development and not leaving technical debts for later or for other developers, these technical debts eventually become a problem or a legacy code difficult to modify.
A good coder applies good practices in its development, is creative when providing solutions and above all delivers a product with high quality programming, architects must guide and accompany the development of each developer until they are autonomous. Each Scrum team must support each other and deliver products in their sprint, in case of not being able to deliver, the reason must be identified and continuous improvement must be sought.
Finally, today's world and the world of software development is constantly changing so we must adapt to change with an evolutionary architecture, then the architect must live with the system to make improvements. Just as micro-services are being implemented today every architect must read books, learn design patterns and keep up to date every day.
## Important points
- A Software Architect must be in constant training.
- An important characteristic of an Architect is to have soft skills with product owners, teams, etc.
- Once a requirement is finalized and in DONE move to production as soon as possible.
- The decisions made influence the life of the software.
### References
- Success Skills for Architects with Neil Ford page https://www.se-radio.net/se-radio-episode-287-success-skills-for-architects-with-neil-ford/
================================================================================
## Post: 2021-14-06-Success-Skills-for-Architects
Source file: _posts/2021-14-06-Success-Skills-for-Architects.md
================================================================================
---
layout: post
title: "Summary About: \n Success Skills for Architects with Neil Ford - Spanish"
modified:
categories:
excerpt: >
Mis notas acerca de buena arquitectura
tags: []
image:
feature:
date: 2021-06-15T08:08:53-07:00
---
This article was extracted from [Potcast Episode 287 for Neil Ford](http://www.se-radio.net/2017/04/se-radio-episode-287-success-skills-for-architects-with-neil-ford/).
## Resumen
En este Postcast encontraremos varios consejos sobre habilidades y estrategias para ser un buen arquitecto de software, a continuación presentaré un resumen de este podcast el cual es muy interesante sobre las experiencia de Neil Ford.
Todas las personas que estén involucradas con el desarrollo de software llegan a tomar decisiones en la misma, pero el arquitecto es quien debe tener amplio conocimiento sobre las tecnologías, habilidades técnicas y además de tener habilidades blandas para comunicarse con los usuarios, gerentes y el equipo de desarrollo. Los arquitectos deben estar en constante capacitación con otros arquitectos para adquirir conocimiento, también el arquitecto debe poder ser un líder en su entorno, a continuación veamos alguna características de un buen arquitecto de software:
- Tener vision en las decision de arquitectura definidas.
- Comprender y conocer tecnologías, y multiples maneras de implementar la arquitectura.
- Tener habilidades blandas.
- Poseer conocimientos en términos como seguridad, escalabilidad, confiabilidad, mantenibilidad etc.
Por lo tanto un arquitecto debe tener varias habilidades y conocimiento por lo cual nunca debe dejar de capacitarse, entre las habilidades con el equipo de desarrollo el arquitecto de promover la programación en pareja, definir una representación sobre la arquitectura utilizada la cual servirá al equipo y los usuarios, como por ejemplo el Modelo C4 el cual es una representación por niveles muy fácil de aplicar y de mucha utilidad. También se recomienda tener registrada todas las decisiones técnicas para futuras decisiones.
Cuando se desarrolla un software es importante tomar buenas decisiones sobre las cosas que utilizamos porque todo esto podría conducir al fracaso o éxito del software, estas decisiones son importante compartirlas con todo el equipo y en especial con los nuevos. Cada componente del software es importante por lo cual se debe dedicar un tiempo considerable en la codificación de dichos componentes, acompañados de buenas prácticas en el desarrollo y no dejando deudas técnicas para más tarde o para otros desarrolladores, estas deudas técnicas con el tiempo se vuelven un problema o un código legado difícil de modificar.
Un codificador bueno aplica buenas prácticas en su desarrollo es creativo al momento de dar soluciones y por sobre todo entrega un productos con alta calidad de programación, los arquitectos deben guiar y acompañar el desarrollo a cada desarrollador hasta que sean autónomos. Cada equipo Scrum debe apoyarse y sacar productos en su sprint en caso de no poder realizar entregables se debe identificar el porqué y tratar de realizar una mejora continua.
Finalmente el mundo actual y el de desarrollo de software cambia constantemente por lo cual debemos adecuarnos al cambio con una arquitectura evolutiva, entonces el arquitecto de vivir con el sistema para realizar mejoras. Así como los micro-servicios se están implementando en la actualidad cada arquitecto debe leer libros, aprender patrones de diseño y mantenerse actualizado cada día.
## Puntos importantes
- Un Arquitecto de Software debe estar en constante Capacitación
- Una característica importante de un Arquitecto es tener habilidades blandas con los dueños del producto, equipos, etc.
- Una vez finalizado un requerimiento y este en DONE mover a producción tan pronto como sea posible.
- Las decisiones tomadas influyen en la vida del software.
### Referencias
- Success Skills for Architects with Neil Ford page https://www.se-radio.net/se-radio-episode-287-success-skills-for-architects-with-neil-ford/
================================================================================
## Post: 2021-30-05-a-good-architecture
Source file: _posts/2021-30-05-a-good-architecture.md
================================================================================
---
layout: post
title: "Una buena Arquitectura de Software - Spanish"
modified:
categories:
excerpt: >
Mis notas acerca de buena arquitectura
tags: []
image:
feature:
date: 2021-05-29T08:23:53-07:00
---
# A good Software Architecture
## Resumen
En la actualidad los productos de software son muy variados y por lo tanto se utiliza una variedad de arquitecturas de software. Las cuales demuestran el éxito de un proyecto de software y la aceptación como una buena arquitectura, es por eso que en este ensayo estaremos hablando acerca de los beneficios, practicas, recomendaciones y conceptos fundamentales para llegar a tener una buena arquitectura de software. Debo mencionarles que no se hablara acerca de tecnologías porque estas cambian rápidamente en nuestra profesión.
## Contexto
Entonces empecemos hablando sobre ¿Qué es una Arquitectura de Software?, No existe una definición correcta para referirse a qué es la Arquitectura de Software. Sin embargo existen varias definiciones que tienen el mismo concepto, Ejemplo "Una Arquitectura de Software representa la estructura o estructura del sistema, que consta de componentes de software, las propiedades visibles externas de esos componentes y la relación entre ellos.", teniendo como base la anterior definición podemos comentar e inferir que la arquitectura de software no solo se limita a definir los componentes y sus relaciones, sino a tener claro las relaciones entre objetos, identificación de tecnologías adecuadas para construir el sistemas, por otro lado es importante entender los requisitos no funcionales del sistema, documentar y comunicar a las partes interesadas.
## Cuerpo
La Arquitectura de Software sirve como vision de un plano para el equipo de desarrollo de software quienes estarán implementando los requerimientos del negocio puedan tener mejor idea. La arquitectura de software no es un plano estático mas al contrario es un proceso de evolución en estrategias, técnicas, patrones de diseño, diseños arquitectónicos y componentes. Al construir una buena arquitectura podremos identificar los riesgos de diseño y mitigarlos con anticipación.
Algo que he aprendido con los años de experiencia en el desarrollo de software es que ni siquiera el cliente sabra lo que quiere. Por lo tanto es importante tener algún documento para todos los requerimientos funcionales y no funcionales, ademas de una serie de entrevistas con todos los involucrados al software, todo esto con el objetivo de entender el negocio. De esta manera podremos definir una arquitectura base acorde a las necesidades del cliente, también se podrá definir las tecnologías que se adecuen al sistema.
A continuación responderemos las siguientes preguntas:
- ### Which criteria do you use to define such architecture as good?
Hay muchos criterios de calidad del sistema que podemos discutir, pero para mí, las siguientes características de la arquitectura son una base sólida para obtener una buena arquitectura de software.
1. **Comprensibilidad**.- Significa que nuestra arquitectura es de fácil de entender por el equipo de desarrollo y las partes interesadas, al mismo tiempo debe abarcar todos los requisitos del negocio.
2. **Facilidad de uso y Aprendizaje**.- Este punto esta relacionado con los requerimientos de UX/UI lo cual es importante al momento de definir la tecnología en la que se desarrollara el software. Los arquitectos deben ser consciente a la hora de definir la tecnología y la arquitectura.
3. **Seguridad**.- Es un factor importante para el software, consiste en restringir el acceso de los usuarios ó componente basándose en la autenticación. De esta manera se podrá proteger de ataques DDoS, inyección de SQL y alertar al sistema. De esta manera se resguardaran los datos.
4. **Fiabilidad y Disponibilidad**.- Es muy importante en el diseño de la arquitectura de software porque las fiabilidad es un atributo del sistema responsable de la capacidad de seguir funcionando en condiciones predefinidas y la Disponibilidad representa que el sistemas estará funcionando el 99,9 %, caso contrario se debe tener medidas de contingencia como correos, notificaciones.
5. **Interoperabilidad**.- La mayoría de los servicios de las aplicaciones deben comunicarse con sistemas externos para proporcionar servicios completos. Una arquitectura de software bien diseñada facilita la interoperabilidad de la aplicación para comunicarse e intercambiar datos con sistemas externos o sistemas heredados.
6. **Testablidad**.- La base de una buena arquitectura de software se base en asegurase de que el diseño de cada componente sea testeable. Una arquitectura testable debe mostrar claramente todas las interfaces, y la integración entre los componentes. Todos los requisitos funcionales y no funcionales (NFR) del negocio deben ser coherentes y completamente comprobables. Asegúrese de que todos los entornos DEV, TEST, UAT y PRODUCCIÓN sean similares.
7. **Escalabilidad**.- La arquitectura tecnológica definida debe ser capas de escalar sin afectar el rendimiento. Hay dos tipos de escalado: el escalado vertical y el escalado horizontal. El escalado vertical consiste en añadir más hardware de CPU/memoria/disco al servidor existente. El escalado horizontal consiste en dividir la carga y responder a las peticiones añadiendo más servidores/instancias al clúster de servidores. El escalado horizontal es recomendado.
- ### Which benefits does the architecture provide over the inhabitants of the system?
Los beneficios de una buenas arquitectura son:
1. Crear un plano o base solidad para el proyecto de software
2. Escalabilidad del Proyecto de software.
3. Reduce costos de mantenimiento.
4. Aumenta el rendimiento del Proyecto de software.
5. Mejor mantenibilidad en el código.
6. Permite cambios rápidos en el proyectos.
7. Ayuda en la gestión de riesgos . Ayuda a reducir los riesgos y la posibilidad de fallas.
8. Mayor adaptabilidad para nuevos requerimiento, ya que la arquitectura del software crea una clara separación de preocupaciones.
9. Mejor comunicación con las partes interesadas
10. Auditable y testeable.
- ### Which trade-offs have been made in the system to keep the architecture?
En el Diseño de Arquitectura existen consideraciones importantes a tomar decisiones:
- **Flexibilidad frente a simplicidad**
- **Espacio contra tiempo**
- **Latencia frente a rendimiento**
- **Seguridad, Estabilidad, Mantenibilidad**
- ### Which recommendations for improvements you have over the architecture?
Para el diseño de una buena arquitectura es importante tener un equipo multi-diciplinario y algunos de sus integrantes tengan varios años de experiencia en el desarrollo de software, a continuación voy a listar algunas recomendaciones que utilidad y investigado cuando he desarrollado software.
1. Analizar y Verificar si existen dependencias con componentes, API, externos. En caso de existir se debe definir el protocolo de comunicación.
2. Tener estrecha comunicación con el cliente para conocer el proceso y los requerimientos de la solución.
3. Definir qué patrones de arquitectura se va a utilizar.
4. Definir qué componentes se va utilizar o se va crear.
5. Recomendar que el equipo tenga conocimientos de algunos conceptos como SOLID, KISS, DRY y YAGNI, estos conceptos ayudara a que el equipo pueda realizar un código mantenible.
6. Conocer y aplicar patrones de diseño, refactorización los cuales nos ayudaran a tener un código limpio.
## Conclusión
En este articulo he presentado mis investigaciones he ideas sobre cuáles deberían ser las características de una buena arquitectura de software. Cada una de estas características merece una discusión más larga y también hay otras características que no se tocan.
La arquitectura de software que diseñes siempre debe estar enfocada a lo que necesita el cliente, en entender que es lo que nuestro software va a trabajar y cómo lo va a hacer. Pudiendo ser capaces de conocer los pro y contras de cada opción que tomemos desde antes de empezar a codificar.
================================================================================
## Post: 2023-08-01-clean-code-tips
Source file: _posts/2023-08-01-clean-code-tips.md
================================================================================
---
layout: post
title: Aplicando los Principios de Código Limpio de "Clean Code" en la Práctica
modified:
categories: Refactoring
excerpt: >
Mis notas acerca de buena Código Limpio
tags: []
image:
feature:
date: 2023-08-01T08:12:53-07:00
---
**Objetivo:** El objetivo de este artículo es explorar la aplicación de los principios de código limpio del libro "Clean Code" de Robert C. Martin en ejemplos concretos. Esto promoverá la comprensión y la práctica de las buenas prácticas de programación, resaltando la importancia de escribir código limpio y mantenible en el desarrollo de software.
**Introducción:**
El desarrollo de software es una disciplina en constante evolución, y uno de los desafíos clave es escribir código que sea fácil de entender, mantener y mejorar con el tiempo. El libro "Clean Code" de Robert C. Martin proporciona una guía invaluable sobre cómo lograr esto. En este artículo, exploraremos varios conceptos claves del libro y los ilustraremos con ejemplos prácticos. También destacaremos una cita relevante de cada concepto para enriquecer nuestra comprensión.
**Concepto 1: Nombres Significativos**
**Definición:** Los nombres de variables, funciones y clases deben ser descriptivos y significativos. Los nombres deben comunicar claramente la intención del código y el propósito de la entidad nombrada.
**Resultado:** Facilita la comprensión del código, reduce la necesidad de comentarios excesivos y mejora la mantenibilidad.
**Ejemplo Práctico:** Supongamos que estamos escribiendo una función en Python para calcular el promedio de una lista de números:
```python
def calcular_promedio(lista_de_numeros):
suma = sum(lista_de_numeros)
cantidad = len(lista_de_numeros)
promedio = suma / cantidad
return promedio
```
**Explicación:** Los nombres de variables como `suma`, `cantidad` y `promedio` son descriptivos y comunican claramente su propósito en el cálculo del promedio.
**Cita Relevante:** "El nombre de una variable, función o clase debe revelar su intención" - "Clean Code"
**Concepto 2: Funciones Pequeñas y Concisas**
**Definición:** Las funciones deben ser cortas y hacer una sola cosa. Deben seguir el principio de "una función, una responsabilidad".
**Resultado:** Facilita la comprensión, promueve la reutilización y simplifica las pruebas.
**Ejemplo Práctico:** Consideremos una función en JavaScript que valida si una cadena es un número decimal:
```javascript
function esNumeroDecimal(cadena) {
return !isNaN(cadena) && parseFloat(cadena) === Number(cadena);
}
```
**Explicación:** La función `esNumeroDecimal` es corta y se enfoca en una sola tarea: verificar si una cadena es un número decimal.
**Cita Relevante:** "Las funciones pequeñas son más fáciles de entender que las grandes" - "Clean Code"
**Concepto 3: Comentarios Significativos**
**Definición:** Los comentarios deben utilizarse para explicar el "por qué" detrás del código, no el "cómo". El código en sí mismo debe ser lo suficientemente claro como para no necesitar comentarios explicativos.
**Resultado:** Evita la confusión, mantiene la documentación relevante y facilita las actualizaciones futuras.
**Ejemplo Práctico:** En un programa C++, explicamos por qué se utiliza un algoritmo específico para ordenar una lista de números:
```cpp
// Utilizamos el algoritmo QuickSort porque es eficiente en listas de gran tamaño
void ordenarLista(int lista[], int inicio, int fin) {
// Implementación de QuickSort aquí
}
```
**Explicación:** El comentario explica la elección del algoritmo, lo que puede ser útil para los desarrolladores que trabajan en el código en el futuro.
**Cita Relevante:** "Los comentarios nunca compensan el código pobre" - "Clean Code"
**Concepto 4: Evitar la Repetición**
**Definición:** El código duplicado (repetido) debe ser eliminado. Se debe buscar oportunidades para refactorizar y crear abstracciones que eviten la duplicación.
**Resultado:** Reduce errores, facilita el mantenimiento y mejora la consistencia del código.
**Ejemplo Práctico:** Supongamos que estamos desarrollando un juego en Java y tenemos dos clases que tienen métodos similares para mover personajes:
```java
class Jugador {
void moverArriba() {
// Lógica para mover arriba
}
void moverAbajo() {
// Lógica para mover abajo
}
}
class Enemigo {
void moverArriba() {
// Lógica para mover arriba
}
void moverAbajo() {
// Lógica para mover abajo
}
}
```
**Explicación:** Podríamos crear una clase base común para ambos, eliminando la duplicación de código.
**Cita Relevante:** "La duplicación puede dar lugar a errores sutiles y costosos" - "Clean Code"
**Conclusión:**
La aplicación de los principios de código limpio de "Clean Code" es esencial para crear software de calidad. Los conceptos de nombres significativos, funciones pequeñas y concisas, comentarios significativos y evitar la repetición son fundamentales para escribir código limpio y mantenible. Al seguir estos principios, los desarrolladores pueden mejorar la calidad de su código y facilitar la colaboración en proyectos de desarrollo de software. En última instancia, la búsqueda de la excelencia en la escritura de código es un objetivo que beneficia tanto a los desarrolladores como a los usuarios finales del software.
================================================================================
## Post: 2023-12-24-migration-ibm-aws
Source file: _posts/2023-12-24-migration-ibm-aws.md
================================================================================
---
layout: post
title: 🚀 ¡Migra tu infraestructura de IBM a AWS con éxito! 🚀
modified:
categories: AWS, IBM, Cloud
excerpt: >
Mis experiencia de AWS
tags: []
image:
feature:
date: 2023-12-24T08:12:53-07:00
---
**Contexto:**
En un mundo empresarial cada vez más digitalizado, la migración de infraestructuras de TI hacia entornos en la nube se ha convertido en un imperativo para muchas organizaciones.
En este Post te comparto mi experiencia el proceso de migración, como comprenderas este proceso es extenso largo pero tratare de resumir colocando los pasos mas importantes.
En esta transición de la infraestructura entre Clouds como IBM a AWS las empresas que buscan optimizar sus operaciones, mejorar la escalabilidad y la agilidad, así como reducir costos.
Aquí tienes una lista de 5 tipos de migración que se pueden aplicar en el contexto de la migración de infraestructura de TI:
1. **Clonado:** Consiste en duplicar exactamente la configuración y los datos de una infraestructura en un nuevo entorno, como una copia idéntica de un servidor o una base de datos.
2. **Rehosting (o Lift and Shift):** Esta estrategia implica mover las aplicaciones y los datos de un entorno de origen a un entorno de destino sin realizar cambios significativos en la arquitectura o el código. Es útil para migrar rápidamente aplicaciones existentes a la nube con mínima modificación.
3. **Replatforming (o Lift, Tinker, and Shift):** En esta estrategia, las aplicaciones se ajustan ligeramente para aprovechar las características específicas del entorno de destino, como la optimización de recursos o la adopción de servicios administrados, sin una reconstrucción completa.
4. **Refactoring (o Re-Architecting):** Implica reescribir o modificar significativamente las aplicaciones existentes para aprovechar al máximo las características y servicios nativos de la nube, lo que puede resultar en mejoras significativas en la eficiencia, escalabilidad y mantenibilidad.
5. **Repurchasing (o Rebuy):** Esta estrategia implica reemplazar aplicaciones existentes con soluciones de software como servicio (SaaS) o comprar nuevas soluciones que satisfagan las necesidades de la organización, a menudo eliminando la necesidad de migración de datos.
**Requerimiento:**
Buenos en este Post usaremos **Migración Clonado** con la herramienta [MGN](https://docs.aws.amazon.com/mgn/latest/ug/what-is-application-migration-service.html).
Antes de empesar con la migracion se requiere hacer relevamientos necesarios aqui te muestro algunos puntos tecnicos importantes.
- Diagrama de arquitectura actualizado (con los nombres de los recursos)
- Accesos a la cuentas Cloud
- Obtener el inventario de versiones de sistema operativo, binarios, lenguaje de programación.
- Mapeo de dominios y subdomionios
- Diagnosticar el impacto de la migración de dominios
- Obtener volumetría de datos en Bases de Datos
- Planificación
Ejemplo de Planificacion
**Proceso Técnico:**
La migración técnica de la infraestructura de IBM a AWS implica una serie de pasos cruciales:
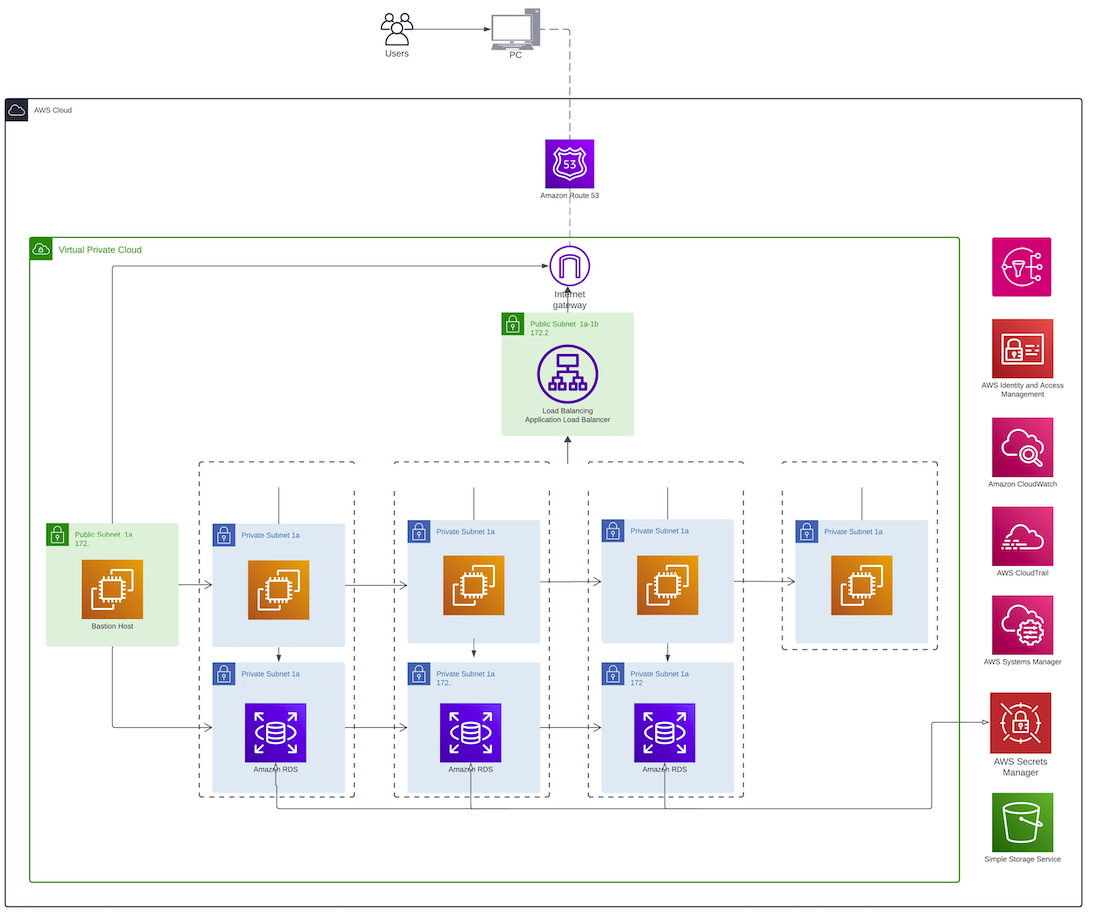
1. **Evaluación de la infraestructura existente:** Comienza con un análisis exhaustivo de la infraestructura de TI actual en IBM, identificando servidores, bases de datos, aplicaciones y otros recursos que necesitan ser migrados.
2. **Selección de servicios equivalentes en AWS:** Identifica los servicios de AWS que mejor se ajustan a las necesidades de la empresa, como EC2 para servidores virtuales, RDS para bases de datos y S3 para almacenamiento.
3. **Planificación de la migración:** Desarrolla un plan detallado que incluya fechas de inicio y finalización, recursos necesarios, requisitos de seguridad y estrategias de respaldo y recuperación.
4. **Configuración de la infraestructura en AWS:** Configura los recursos necesarios en AWS, como instancias EC2, bases de datos RDS, grupos de seguridad y otros servicios relevantes.
5. **Migración de datos:** Transfiere los datos de los sistemas en IBM a AWS, incluyendo bases de datos, archivos y aplicaciones críticas.
6. **Pruebas y optimización:** Realiza pruebas exhaustivas para garantizar que todos los sistemas funcionen correctamente en el entorno de AWS. Esto incluye pruebas de rendimiento, seguridad y continuidad del negocio.
7. **Implementación:** Despliega los sistemas en producción y asegúrate de que estén funcionando correctamente. Proporciona soporte continuo para abordar cualquier problema que pueda surgir durante la transición.
**Proceso Comercial:**
La migración de IBM a AWS también requiere una cuidadosa consideración de los aspectos comerciales:
1. **Identificación de necesidades comerciales:** Comprende los objetivos y necesidades comerciales de la organización para garantizar que la migración a AWS esté alineada con la estrategia general de la empresa.
2. **Análisis de costos:** Realiza un análisis detallado de los costos asociados con la migración a AWS, incluyendo infraestructura, licencias de software, servicios profesionales y otros gastos relacionados.
3. **Desarrollo de un caso de negocio:** Utiliza los resultados del análisis de costos para desarrollar un caso de negocio convincente que demuestre los beneficios de migrar a AWS, como ahorros en costos operativos y mejoras en la escalabilidad y la disponibilidad.
4. **Negociación con AWS:** Negocia los términos y condiciones del acuerdo con AWS, incluyendo precios, niveles de servicio y compromisos de uso.
5. **Planificación de la transición:** Desarrolla un plan detallado para la transición de IBM a AWS, teniendo en cuenta los requisitos comerciales y técnicos de la empresa.
6. **Comunicación y capacitación:** Comunica los detalles de la migración a todas las partes interesadas y proporciona capacitación adecuada sobre cómo utilizar los servicios de AWS.
**Conclusiones:**
La migración de la infraestructura de IBM a AWS es un proceso complejo que requiere una cuidadosa planificación y ejecución. Sin embargo, con una estrategia bien definida y la colaboración adecuada entre los equipos técnicos y comerciales, las empresas pueden lograr una transición exitosa hacia la nube. Al migrar a AWS, las organizaciones pueden beneficiarse de una mayor flexibilidad, escalabilidad y agilidad, allanando el camino hacia la innovación y el crecimiento empresarial en el futuro digital.
================================================================================
## Post: 2025-01-25-Integration-with-Multiple-Payment-Gateways
Source file: _posts/2025-01-25-Integration-with-Multiple-Payment-Gateways.md
================================================================================
---
layout: post
title: 📝 Integration with Multiple Payment Gateways
modified:
categories: Payments, Stripe,Paypal
excerpt: >
Mis experiencia con 3Ds
tags: []
image:
feature:
date: 2025-01-25T08:12:53-07:00
---
## 📝 **Integración con Múltiples Pasarelas de Pago**
En el mundo del software como servicio (SaaS) y el comercio electrónico, procesar pagos de forma fiable y flexible no es solo una necesidad técnica: es el corazón del negocio.
En mis más de 10 años como ingeniero de software, he liderado la integración de pasarelas de pago globales como **Stripe**, **PayPal** y **RazorPay**, así como regionales como **BAC**, **HDLeon**, **PayFast** y otras. En todos estos proyectos, aprendí una verdad fundamental:
> ✅ *El verdadero reto no es conectar una API, sino diseñar una arquitectura que te permita agregar o reemplazar una pasarela sin romper nada ni duplicar esfuerzo.*
Hoy quiero compartir una guía práctica con estrategias, patrones y ejemplos reales que te permitirán construir un sistema de pagos modular, extensible y fácil de mantener.
---
### 🧩 1. Desafíos Comunes al Integrar Pasarelas
🔍 Aunque las pasarelas de pago comparten propósito, cada una tiene sus propias reglas, flujos y APIs. Algunos desafíos típicos:
* **APIs heterogéneas:** Lo que en Stripe es un `PaymentIntent`, en otros casos es una combinación de `token + confirmación`. La semántica cambia.
* **Errores y asincronía:** Cada proveedor maneja códigos de error y callbacks (como 3D Secure, OXXO o QR) de forma distinta.
* **Mantenimiento y sandbox:** Integrar múltiples entornos de prueba es engorroso, y los cambios en producción de una pasarela pueden romper el flujo si no tienes una arquitectura robusta.
---
### 🧱 2. Principios de Arquitectura Aplicados
La clave para escalar sin caos es diseñar pensando en el cambio. Estos son los principios que aplicamos con éxito:
* **Open/Closed Principle:** Nuestro motor de pagos está abierto a extensiones (nuevas pasarelas), pero cerrado a modificaciones.
* **Separación de responsabilidades:** La lógica de negocio no sabe nada de las APIs externas. Todo lo maneja un adaptador.
* **Contrato común:** Usamos una clase base (`PaymentService::Gateway::Base`) que obliga a cada pasarela a implementar el método `call`.
```ruby
class PaymentService::Gateway::Base
include Interactor
def call
raise NotImplementedError
end
end
```
---
### 🧠 3. Patrón de Estrategia para Selección Dinámica
Cuando un usuario realiza un pago, nuestro sistema selecciona automáticamente la pasarela adecuada basándose en la configuración de su empresa (`empresa`).
```ruby
def payment_gateway
"#{gateway_namespace}::#{gateway_name}::#{action_name}".constantize
end
```
Ejemplo real:
* Llamas a `PaymentService::Sale.call(...)`
* Si la `empresa` usa Stripe, se ejecuta `PaymentService::Gateway::Stripe::Sale.call(...)`
* Si usa BAC, se ejecuta `PaymentService::Gateway::BAC::Sale.call(...)`
Esto nos permite escalar sin tocar el core.
---
### 🪝 4. Webhooks: La Parte Más Crítica
Procesar webhooks de manera segura y ordenada es indispensable:
* Verificamos firmas con HMAC o JWT
* Usamos un `WebhookProcessor` que delega según el proveedor
* Manejamos idempotencia para evitar duplicados
* Cada pasarela tiene su handler: `Webhooks::StripeHandler`, `Webhooks::MERUHandler`, etc.
---
### 🧪 5. Pruebas y CI/CD
Las pruebas en sistemas de pago son complejas, pero posibles:
* **Unitarias:** Mockeamos respuestas de APIs externas para validar la lógica interna.
* **Por contrato:** Validamos que las firmas, campos obligatorios y flujos 3DS sigan siendo consistentes.
* **Flujo completo:** Simulamos reservas o ventas completas que requieren callbacks o redirecciones.
Además, evitamos ambientes sandbox inconsistentes usando registros grabados (`VCR`, `WebMock`).
---
### 🚀 6. Caso Real: Integración con PayFast
Integrar **PayFast**, un gateway popular en Sudáfrica, tomó menos de 2 semanas gracias a esta arquitectura:
1. Creamos `PaymentService::Gateway::PayFast::Sale`
2. Implementamos el handler de webhooks
3. Configuramos la `empresa` para usar PayFast
4. Sin modificar una línea del core
---
### 📊 7. Impacto Real en el Negocio
Esta arquitectura nos permitió:
✅ Entrar rápidamente a nuevos países
✅ Ofrecer más opciones al usuario final
✅ Cambiar o eliminar pasarelas obsoletas sin fricción
✅ Ahorrar cientos de horas en mantenimiento
✅ Minimizar errores humanos en integraciones sensibles
---
### 🧭 8. Reflexión Final
Invertir en una arquitectura de pagos limpia es una decisión estratégica. En lugar de reescribir todo con cada nuevo proveedor, construyes una base sólida para el futuro.
Si estás por integrar tu segunda o tercera pasarela, ¡detente y piensa en la arquitectura! Vale más hacerlo bien una vez que mal diez veces.
================================================================================
## Post: 2025-01-28-Seguridad_en_Transacciones_3DS
Source file: _posts/2025-01-28-Seguridad_en_Transacciones_3DS.md
================================================================================
---
layout: post
title: 🛡️🔒 ¡Seguridad en Transacciones 3DS! 🔒🛡️
modified:
categories: 3Ds, Card, Payments
excerpt: >
Mis experiencia con 3Ds
tags: []
image:
feature:
date: 2025-01-28T08:12:53-07:00
---
# "Seguridad en Transacciones 3DS: Experiencias para Desarrolladores (O Cómo Evitar que tu Sistema de Pagos se Convierta en un Circo)"
En el mundo actual de los pagos digitales, garantizar la seguridad en las transacciones es tan esencial como tener café en una reunión matutina de programadores. La autenticación 3DS (Three-Domain Secure) se ha convertido en un pilar fundamental para proteger tanto a usuarios como a empresas. En este post, compartiré mis experiencias implementando flujos 3DS en sistemas de pago, abordando mejores prácticas, errores comunes y consideraciones de UX para mantener altas las tasas de conversión (y evitar que tus usuarios huyan despavoridos).
## ¿Qué es 3DS y por qué es importante?
3DS es un protocolo de seguridad diseñado para prevenir fraudes en las transacciones en línea. Es como ese amigo paranoico que siempre pregunta "¿estás seguro?" antes de hacer cualquier cosa – pero en este caso, ¡realmente lo necesitamos! Mediante un proceso de autenticación adicional, este sistema ayuda a verificar que el titular de la tarjeta sea quien realmente realiza la compra, reduciendo así el riesgo de transacciones no autorizadas. Porque, seamos honestos, nadie quiere descubrir que "alguien" compró cinco televisores de última generación con su tarjeta mientras dormía plácidamente.
## Implementación de flujos 3DS: Buenas prácticas (o cómo no convertir tu checkout en una prueba de obstáculos)
### Integración fluida con la experiencia del usuario:
Asegúrate de que el proceso de autenticación no interrumpa la experiencia de compra más que una actualización de Windows en plena presentación importante. La comunicación clara y el diseño intuitivo son esenciales para evitar que los usuarios abandonen el proceso y se vayan a comprar a la competencia (o peor aún, a Amazon).
En mi experiencia implementando 3DS, el flujo típico funciona así: tu frontend envía solo los IDs del producto y descuentos al backend, donde realizas todos los cálculos sensibles antes de conectarte al proveedor de pagos. Pro-tip: agrega encriptación entre frontend y backend, porque nunca sabes cuándo algún hacker aburrido decidirá que tu sistema es su próximo proyecto de fin de semana.
Cuando integras con una pasarela de pagos, te ofrecerán opciones con y sin 3DS. Con 3DS, generalmente consumirás un servicio que te devolverá un HTML, te redireccionará a su sitio, o te proporcionará un SDK con el formulario 3DS. Este componente suele ser personalizable en colores.
Dependiendo del proveedor, la respuesta puede ser síncrona o asíncrona vía webhook. Para manejar esto, necesitarás almacenar temporalmente la información de la transacción en tu base de datos o Redis, generando un UUID único para completar el flujo. Es como dejar una nota para tu yo del futuro diciendo "Hey, recuerda completar esta transacción cuando el banco responda".
### Pruebas exhaustivas:
Realiza pruebas de extremo a extremo en diferentes escenarios como si fueras un detective obsesivo: diferentes dispositivos, navegadores y condiciones de red. Porque si tu sistema 3DS funciona perfectamente en Chrome pero falla en Safari, tendrás a todos los usuarios de Apple enviándote correos electrónicos más salados que las palomitas del cine.
Coordina con tu proveedor si se requiere algún proceso de certificación. Por experiencia, en LATAM estos procesos suelen ser más cortos que un sprint de desarrollo, mientras que en Asia son más largos que la documentación de un proyecto legacy.
Como desarrollador, serás el primero en probar la integración, así que conocerás todos los posibles errores antes que nadie (¡felicidades por este dudoso honor!). Luego, pásalo al equipo de QA para una segunda revisión. Si puedes conseguir clientes beta para probar, mejor aún - ellos encontrarán errores que ni siquiera sabías que eran posibles.
Y no olvides hacer pruebas en producción sacrificando algunos dólares. Sí, tu departamento de finanzas te mirará raro cuando vea "Gastos de prueba: $10" en el informe, pero es mejor que explicar por qué todos los pagos fallan en producción.
### Actualización constante:
Mantente al día con las últimas versiones y recomendaciones del protocolo 3DS. Las actualizaciones pueden incluir mejoras de seguridad que protejan tanto a la plataforma como a sus usuarios. Recuerda: en el mundo de la seguridad digital, quedarse atrás es como usar "password123" como contraseña en 2025.
### Monitoreo y análisis:
Implementa herramientas de monitoreo para detectar comportamientos anómalos y medir la tasa de conversión en cada fase del flujo. Porque sin datos, estás tan a ciegas como un murciélago en una discoteca con luces estroboscópicas.
Para esto, puedes usar herramientas como Kibana, Sentry, CloudWatch de AWS, o cualquier otra que tu equipo conozca y esté dispuesto a implementar (o sea, la que alguien del equipo ya haya usado y pueda configurar sin tener que leer toda la documentación).
Prepárate para dar soporte al menos durante un mes después del lanzamiento. Los logs serán tus mejores amigos - o tus peores enemigos si olvidaste registrar la información correcta. Asegúrate de almacenar suficientes datos para reconstruir el flujo cuando algo falle a las 3 AM y tengas que depurar medio dormido.
## Errores comunes a evitar (o cómo no sabotear tu propio sistema)
### Interrupciones innecesarias:
Un flujo de autenticación demasiado complejo es como pedir 17 documentos para entrar a una fiesta. Evita pasos redundantes y asegúrate de que cada interacción aporte valor a la seguridad sin sacrificar la usabilidad. Nadie quiere sentir que está aplicando para un préstamo hipotecario cuando solo quiere comprar calcetines.
Si el proceso de pago toma más de 15 segundos, prepárate para ver a tus usuarios abandonar más rápido que desarrolladores en una reunión de planificación que se extiende después de las 5 PM.
Coordina estrechamente con tu proveedor y tu equipo. Si encuentras impedimentos, comunícalos inmediatamente a tu líder. Y si descubres un error en producción o estimaste mal los tiempos (¿quién no lo ha hecho?), informa a tu equipo de inmediato. Recuerda: el único error imperdonable es el que ocultas hasta que explota.
### Falta de personalización:
No todos los usuarios son iguales, igual que no todos los desarrolladores sobreviven con la misma cantidad de café. Considera estrategias que permitan adaptar el proceso de autenticación según el perfil del usuario o el nivel de riesgo de la transacción. Tu abuela de 80 años comprando flores online no necesita el mismo nivel de seguridad que alguien adquiriendo criptomonedas a las 3 AM.
### Mala integración con el sistema de pagos:
Una integración deficiente puede llevar a errores de comunicación entre los sistemas, como esa pareja que no se habla después de una discusión. Es vital trabajar de cerca con proveedores y socios tecnológicos para asegurar una implementación robusta. Porque cuando los sistemas no se comunican bien, el único mensaje que recibe el usuario es "Error desconocido" (la frase más temida en el universo digital, justo después de "Hemos actualizado nuestra política de privacidad").
Al iniciar la integración, solicita toda la documentación posible: Postman collections, videos de uso, Swagger, y lo más importante: un número de teléfono y correo para consultas. Por experiencia, crear grupos de WhatsApp, Slack o Teams con el proveedor acelera la resolución de problemas. Los correos pueden tardar entre 1 y 24 horas en ser respondidos, tiempo suficiente para que tu ansiedad construya un castillo y lo derrumbe varias veces.
## Consideraciones de UX para mantener la conversión (o cómo no espantar a tus clientes)
La seguridad no debe estar reñida con una buena experiencia de usuario, igual que la pizza no debería estar reñida con la piña (aunque esto último sigue siendo controvertido y podría iniciar una guerra civil en tu equipo de desarrollo).
### Claridad en la comunicación:
Informa al usuario sobre cada paso del proceso de autenticación. Mensajes claros y precisos ayudan a reducir la ansiedad y a generar confianza. "Estamos verificando tu identidad" suena mucho mejor que "Procesando... espere... procesando..." durante 30 segundos de silencio incómodo que hace que el usuario se pregunte si debería refrescar la página (spoiler: no debería).
### Optimización para dispositivos móviles:
Dado el creciente uso de smartphones para realizar pagos (porque, ¿quién usa computadoras de escritorio estos días?), el flujo 3DS debe estar completamente optimizado para dispositivos móviles, con tiempos de carga más rápidos que las excusas de un desarrollador cuando le preguntan cuándo estará lista la función prometida para "finales de semana".
### Feedback en tiempo real:
Proporciona retroalimentación inmediata en caso de errores o validaciones. Esto permite que el usuario corrija rápidamente cualquier inconveniente sin sentirse más perdido que un programador junior en una reunión de arquitectura donde todos hablan en acrónimos que nadie se molesta en explicar.
## Conclusión
Implementar un flujo 3DS robusto es un balance entre fortalecer la seguridad y mantener una experiencia de usuario óptima, algo así como intentar comer saludable pero no renunciar completamente al chocolate. Siguiendo estas mejores prácticas y evitando los errores comunes, los desarrolladores pueden crear sistemas de pago seguros que no afecten negativamente las tasas de conversión.
En mi experiencia liderando integraciones de pago, he aprendido que la comunicación clara con proveedores, usuarios y equipo es tan importante como el código mismo. En un entorno donde la confianza del cliente es fundamental, invertir en un proceso de autenticación eficiente y amigable es clave para el éxito a largo plazo.
¿Qué estrategias han implementado en sus proyectos para optimizar la seguridad sin comprometer la experiencia del usuario? ¿Alguna vez han tenido que lidiar con un sistema 3DS tan complicado que parecía diseñado por un comité de gatos caminando sobre teclados? ¿O quizás han experimentado ese momento de pánico cuando un pago falla en producción y el cliente es el CEO de la empresa? ¡Los leo en los comentarios!
================================================================================
## Post: 2025-06-01-Trazabilidad_en_Transacciones_3DS
Source file: _posts/2025-06-01-Trazabilidad_en_Transacciones_3DS.md
================================================================================
---
layout: post
title: 🛡️🔒 Seguridad y Trazabilidad en Transacciones de Pagos 🔍💳
modified:
categories: [3DS, Card, Payments]
excerpt: >
Descubre cómo diseñamos una arquitectura robusta para trazabilidad de pagos 3DS en sistemas distribuidos. De la incertidumbre al diagnóstico preciso.
tags: [3DS, Payments, Ruby on Rails, Logging, Observability]
image:
feature:
date: 2025-6-24T08:12:53-07:00
---
## 🧵 El Hilo Invisible: Trazabilidad en el Caos Distribuido
> _“El pago falló.”_
Tres palabras que pueden parecer simples, pero en el contexto de un sistema distribuido, suenan como una alarma en medio de la noche. Para nosotros, los desarrolladores, no son solo un error: son el inicio de una búsqueda a través de múltiples servicios, servidores y eventos asincrónicos que, muchas veces, no hablan entre sí.
En plataformas que procesan miles de transacciones por minuto, los logs tradicionales no son la solución. Son parte del problema. Por eso, en este artículo quiero compartir contigo una estrategia real y probada, que convierte el caos en claridad: **trazabilidad de punta a punta** en flujos de pago con 3DS.
---
## 🔥 El Problema: Diagnóstico en la Oscuridad
Imagina este flujo típico de una transacción:
1. El usuario hace clic en **"Pagar"**.
2. La petición llega al backend (por ejemplo, en el `servidor-03`).
3. Se ejecuta la lógica que interactúa con la **pasarela de pago**.
4. Unos minutos después, llega un **webhook** a otro servidor (`servidor-08`).
5. Ese webhook dispara un **WebSocket** para actualizar al usuario en tiempo real.
Ahora... algo falla. ¿Dónde está el error? ¿Se cayó el webhook? ¿La pasarela no respondió? ¿El socket nunca se emitió?
Peor aún: el equipo comercial solo te da el correo del usuario y te dice *"revisá por qué no le llegó el cobro"*. Sin trazabilidad, estás buscando una aguja en un pajar.
---
## 🧠 La Solución: `trace_id`, Nuestro Hilo de Ariadna
Para unir todos los puntos de ese flujo, necesitas un **ID de correlación**. Ese `trace_id` nace al inicio de la solicitud y vive durante todo el recorrido, de extremo a extremo.
Con él:
- Tienes **contexto compartido** entre servicios.
- Puedes **reconstruir el flujo completo** en herramientas como Kibana o Datadog.
- Evitas depender de logs desordenados y fragmentados.
---
## 🛠️ Cómo lo Implementamos
### 1. `CurrentAttributes`: Contexto Seguro y Limpio
Usamos `ActiveSupport::CurrentAttributes` para mantener el `trace_id` accesible, sin tener que pasarlo como parámetro entre métodos. Un middleware o filtro en el controlador base hace lo siguiente:
- Revisa si el header de la petición ya trae un `trace_id`.
- Si no existe, genera un `UUID` nuevo y lo guarda como contexto global.
Esto asegura que cada flujo tenga un identificador único y consistente.
---
### 2. Módulo de Logging Reutilizable
Creamos un módulo (`PaymentLogger`, por ejemplo) con un solo método:
```ruby
log_payment_event(tag:, data:)
````
Este método:
* Enriquecer automáticamente cada log con:
* `trace_id`
* `timestamp`
* `hostname`
* Datos del usuario (si están disponibles)
* Formatea los logs como JSON estructurado.
* Ofusca datos sensibles como tarjetas, emails, tokens, etc.
De esta forma, el logging no es una tarea, sino una característica clave del sistema.
---
### 3. Instrumentación Estratégica
Aplicamos `log_payment_event` en los puntos críticos del flujo, ejemplos en ruby on rails:
#### 🟢 Inicio (API Controller)
```ruby
log_payment_event(tag: 'payment_flow.started', data: { params: request.params })
```
#### 🔁 Interacción con Pasarela (Service Layer)
```ruby
log_payment_event(tag: 'payment_gateway.request', data: { gateway_params: ... })
log_payment_event(tag: 'payment_gateway.response', data: { response: ..., status: 'success' })
```
#### 📩 Webhook (Confirmación Asíncrona)
* Extraemos el `order_id` del webhook.
* Lo usamos para setear nuevamente el `trace_id`.
```ruby
log_payment_event(tag: 'webhook.received', data: { payload: ... })
```
#### 📡 WebSocket (Notificación al Usuario)
```ruby
log_payment_event(tag: 'socket.emitted', data: { channel: ..., event: ... })
```
---
## 🔍 Resultado: Diagnóstico en Tiempo Real
Cuando alguien del equipo de soporte te da un `user_id`, simplemente haces esto:
1. **Buscas el `user_id` en Kibana:**
`json.context.user_id: "12345"`
2. **Extraes el `trace_id`:**
`"uuid-abc-123"`
3. **Rastreás todo el flujo:**
`json.trace_id: "uuid-abc-123"`
Y así obtienes toda la historia: solicitud, respuesta, webhook, socket… todo en orden y con contexto.
---
## 🎯 Conclusión: Trazabilidad es Confiabilidad
Diseñar un sistema de trazabilidad no es un lujo, es un requisito. En plataformas de pagos con 3DS, donde los errores pueden costar dinero (y reputación), no tener visibilidad es inaceptable.
Con un enfoque basado en `trace_id`, logs estructurados y contexto compartido, transformamos un sistema opaco en una máquina transparente, confiable y lista para escalar.
> *La próxima vez que leas “el pago falló”, no sentirás pánico. Tendrás el mapa.*
---
================================================================================
## Post: 2025-08-15-definition-of-ready-definition-of-done
Source file: _posts/2025-08-15-definition-of-ready-definition-of-done.md
================================================================================
---
layout: post
title: Definition of Ready y Definition of Done - Los guardianes de la calidad en desarrollo ágil
modified:
categories: Agile, Software Engineering, Best Practices
excerpt: >
Cómo DoR y DoD transforman el caos en un proceso predecible y de alta calidad
tags: []
image:
feature:
date: 2025-08-15T08:12:53-07:00
---
## Introducción: El problema del "casi listo"
¿Cuántas veces has escuchado esto en tu carrera?
* "Esta tarea está lista para desarrollar" → Te sientas a trabajar y te faltan 10 piezas de información
* "Este feature está terminado" → Lo deploys y encuentras 5 bugs en producción
* "Solo falta un detallito" → Ese detallito toma 3 días más
En mis más de 10 años desarrollando software, he visto equipos paralizados por la falta de claridad sobre dos preguntas fundamentales:
1. **¿Cuándo una tarea está realmente lista para empezar?**
2. **¿Cuándo un feature está realmente terminado?**
La respuesta a estas preguntas son dos conceptos que separan equipos amateur de equipos profesionales:
* **Definition of Ready (DoR)** - El contrato de entrada
* **Definition of Done (DoD)** - El contrato de salida
> Este artículo es una guía práctica y técnica sobre cómo implementar DoR y DoD en equipos de desarrollo modernos, con ejemplos reales de sistemas complejos que gestionan pagos, reservaciones y operaciones críticas.
---
## 1. ¿Qué es Definition of Ready (DoR)?
**Definition of Ready es el checklist que asegura que una historia de usuario tiene suficiente claridad, contexto y detalle antes de que el equipo comience a trabajar en ella.**
### El costo de no tener DoR
Sin DoR, esto es lo que pasa:
* El desarrollador empieza a trabajar y descubre que falta información → **Bloqueo**
* Hace suposiciones incorrectas → **Retrabajo**
* Interrumpe a PM/Product constantemente → **Pérdida de foco**
* Las estimaciones están mal porque no había contexto completo → **Sprint fallido**
**Caso real que viví:**
Un desarrollador tomó un ticket que decía "Arreglar bug en pagos". Sin DoR:
* No sabía qué gateway estaba fallando (Stripe, PayPal, BAC?)
* No sabía cómo reproducir el bug
* No sabía el impacto (¿cuántos usuarios afectados?)
* Pasó 4 horas investigando antes de poder empezar
Con DoR, esas 4 horas se habrían ahorrado.
---
## 2. Criterios de DoR - El Checklist Definitivo
### 2.1 Contexto y Justificación
**Qué debe incluir:**
- Título descriptivo con número de ticket
- El "por qué" de la funcionalidad
- Valor de negocio o problema que resuelve
- Módulo/área del sistema afectada
**Ejemplo real:**
**❌ Mal (sin DoR):**
```
Ticket: Arreglar rangos de edad
```
**✅ Bien (con DoR):**
```
PLAT-2768 | Corregir rangos de edad superpuestos en pricing de turnos
**Contexto:**
Los grupos de edad 18-65 y 65-100 se superponen. Un usuario de 65 años
aparece en ambos grupos, causando precios duplicados en facturación.
**Impacto:**
- 150 usuarios afectados en último mes
- Descuadre en reportes financieros
- Confusión en clientes (+10 tickets de soporte)
**Módulo:** Pricing / Reservations
```
### 2.2 Criterios de Aceptación Verificables
**Qué debe incluir:**
- Happy path (caso de éxito)
- Edge cases y escenarios de error
- Validaciones necesarias
- Comportamiento esperado del sistema
**Ejemplo con casos reales:**
```
**Criterios de Aceptación:**
Happy Path:
✅ El rango 18-65 debe cambiar a 18-64
✅ El rango 65-100 permanece sin cambios
✅ Un usuario de 64 años debe tener precio del grupo 18-64
✅ Un usuario de 65 años debe tener SOLO precio del grupo 65-100
Edge Cases:
✅ Usuario sin edad definida → usar precio default
✅ Edad = 0 o negativa → error de validación
✅ Edad > 150 → error de validación
Validaciones:
✅ No puede haber rangos superpuestos
✅ Rangos deben cubrir todas las edades posibles (1-100+)
✅ Precio debe ser mayor a 0
```
### 2.3 Alcance Técnico Definido
**Qué debe incluir:**
- Archivos/módulos probablemente afectados
- Integraciones o dependencias externas
- Migraciones de datos si son necesarias
- Impacto en APIs (GraphQL, REST)
- Cambios en packs/packages específicos
**Ejemplo real:**
```
**Alcance Técnico:**
Backend (Ruby on Rails):
- Models: PricingRule, ShiftPrice, AgeGroup
- Validations: AgeGroupValidator (actualizar lógica de rangos)
- Services: PricingCalculator (recalcular para edades límite)
- Migrations: UpdateOverlappingAgeRanges
APIs afectadas:
- GraphQL: shiftPricing query
- REST: /api/v1/pricing/calculate (deprecado pero aún en uso)
Frontend:
- React components: PricingForm, AgeRangeSelector
- Redux: pricing slice
Migraciones:
- Actualizar ~500 registros de pricing_rules existentes
- Recalcular precios históricos afectados (opcional)
Packs/Packages:
- Core app (no packs externos)
```
### 2.4 Multi-tenancy y Consideraciones de Scope
Para sistemas SaaS o multi-tenant:
```
**Multi-tenancy:**
- Scope: Por facility (cada instalación tiene sus rangos)
- Timezone: No aplica (edad no depende de timezone)
- Datos existentes: 45 facilities con rangos a actualizar
- Configuración: Migración automática + opción manual post-deploy
**Backward Compatibility:**
- Mobile app v2.3+ soporta nuevos rangos
- Mobile app < v2.3 seguirá usando API legacy (sin cambios)
```
### 2.5 Seguridad y Compliance
```
**Seguridad:**
- Datos sensibles: No (solo rangos de edad, no PII)
- Autorización: Solo admins pueden editar pricing rules (CanCanCan :manage, PricingRule)
- Auditoría: Loggear cambios en pricing_rules_audit_log
- Compliance: No aplica PCI/GDPR
**Permisos requeridos:**
- Desarrollo: :facility_admin o :super_admin
- QA: :facility_admin en staging
```
### 2.6 Plan de Testing
```
**Testing Strategy:**
Unit Tests:
- AgeGroupValidator#validate_no_overlaps
- PricingCalculator#price_for_age(64) → grupo 18-64
- PricingCalculator#price_for_age(65) → grupo 65-100
Integration Tests:
- Crear reserva con usuario edad 64 → precio correcto
- Crear reserva con usuario edad 65 → precio correcto
- Actualizar pricing rule → validaciones funcionan
System Tests (Playwright/Cypress):
- Admin crea nuevo pricing rule con rangos válidos
- Admin intenta crear rangos superpuestos → error visible
Testing Manual:
- Verificar migración en staging antes de producción
- Probar con 3-5 facilities reales
- Validar cálculos históricos no afectados
```
### 2.7 Dependencias y Blockers
```
**Dependencias:**
- PLAT-2750: Refactor de PricingCalculator (debe estar en develop)
- Staging con datos recientes (snapshot de prod < 7 días)
**Blockers:**
- Ninguno identificado
**Riesgos:**
- Migración podría tomar >10min en prod (500k registros)
Mitigación: Ejecutar en horario de bajo tráfico
```
---
## 3. ¿Qué es Definition of Done (DoD)?
**Definition of Done es el checklist que asegura que una historia está completamente terminada, probada, documentada y lista para producción.**
### El costo de no tener DoD
Sin DoD:
* Features "terminados" que rompen en producción
* Tests que faltan o están skippeados
* Documentación que nunca se actualiza
* Code review superficial porque no hay estándar claro
* Deuda técnica que crece exponencialmente
**Caso real:**
Un desarrollador hizo merge de un feature "terminado":
* Funcionaba en su máquina ✅
* Pero no tenía tests ❌
* Rompió el build de CI ❌
* No documentó las variables de entorno nuevas ❌
* Deployment falló en staging ❌
Resultado: 2 días de downtime, 3 desarrolladores bloqueados, PM frustrado, cliente enojado.
Con DoD, esto no habría pasado del code review.
---
## 4. Criterios de DoD - El Checklist de Calidad
### 4.1 Código Implementado y Clean
```
**Checklist:**
✅ Funcionalidad completa según criterios de aceptación
✅ Código sigue convenciones del proyecto (RuboCop, ESLint, Prettier)
✅ No hay código comentado sin justificación
✅ No hay console.log o binding.pry olvidados
✅ Variables tienen nombres descriptivos
✅ Métodos tienen responsabilidad única (SRP)
**Validación:**
bundle exec rubocop -A # Ruby
npm run lint # JavaScript
bundle exec rails runner 'system("packwerk check")' # Pack boundaries
```
### 4.2 Tests Completos y Pasando
**El mínimo aceptable:**
```
**Unit Tests:**
✅ Toda lógica de negocio tiene tests
✅ Edge cases cubiertos
✅ Mocks/stubs usados apropiadamente
✅ Coverage no disminuye (mínimo mantener %)
**Integration Tests:**
✅ Flujos completos end-to-end
✅ Integraciones con servicios externos (Stripe, AWS, etc.)
✅ Background jobs probados
**System Tests (si aplica):**
✅ UX crítica probada (checkout, login, pagos)
✅ Tests no son flaky (usar Timecop, stubs consistentes)
**Validación:**
bundle exec rspec # Todos los tests
SIMPLECOV_REPORT=true bundle exec rspec # Con coverage
bin/test_system system_specs/pricing/ # System tests
```
**Ejemplo de test bien hecho:**
```ruby
# spec/validators/age_group_validator_spec.rb
RSpec.describe AgeGroupValidator do
describe '#validate_no_overlaps' do
context 'when ranges overlap' do
it 'adds error for overlapping ranges' do
rule1 = build(:pricing_rule, age_min: 18, age_max: 65)
rule2 = build(:pricing_rule, age_min: 65, age_max: 100)
validator = AgeGroupValidator.new([rule1, rule2])
expect(validator.valid?).to be false
expect(validator.errors).to include('Age ranges cannot overlap')
end
end
context 'when ranges do not overlap' do
it 'is valid' do
rule1 = build(:pricing_rule, age_min: 18, age_max: 64)
rule2 = build(:pricing_rule, age_min: 65, age_max: 100)
validator = AgeGroupValidator.new([rule1, rule2])
expect(validator.valid?).to be true
end
end
end
end
```
### 4.3 Manejo de Timezone y Time (crítico en apps globales)
```
✅ Usar Time.current en lugar de Time.now
✅ Usar Time.zone.parse en lugar de Time.parse
✅ Respetar timezone de facility/user según contexto
✅ Tests con tiempo usan Timecop.freeze para evitar flakiness
**Ejemplo correcto:**
# ❌ Mal
created_at = Time.now
due_date = Date.today + 7.days
# ✅ Bien
created_at = Time.current
due_date = 7.days.from_now
# ✅ Mejor (con timezone específico)
created_at = Time.current.in_time_zone(facility.timezone)
```
### 4.4 Consideraciones de Pago y Finanzas
Para features que tocan dinero:
```
✅ Usar transacciones de DB para operaciones financieras
✅ Jobs de pago son idempotentes
✅ Validar montos y precisión (cents vs dollars)
✅ Manejar correctamente gateway selection
✅ Loggear TODAS las operaciones financieras
✅ Nunca hacer cálculos con floats (usar Money gem o cents en integers)
**Ejemplo de idempotencia:**
def process_payment(payment_id)
payment = Payment.find(payment_id)
return if payment.processed? # Idempotencia
Payment.transaction do
result = gateway.charge(payment.amount_cents)
payment.update!(
status: 'processed',
gateway_transaction_id: result.id
)
PaymentAuditLog.create!(payment: payment, action: 'processed')
end
rescue Stripe::CardError => e
payment.update!(status: 'failed', error: e.message)
raise
end
```
### 4.5 Background Jobs Robustos
```
✅ Jobs reciben argumentos como hash con symbolized keys
✅ Validar args.is_a?(Hash) antes de procesar
✅ Variables inicializadas antes de rescue blocks
✅ Jobs son idempotentes (pueden ejecutarse múltiples veces)
✅ Retry logic configurado apropiadamente
✅ Dead letter queue para failures críticos
**Ejemplo robusto:**
class ProcessRefundJob < ApplicationJob
queue_as :critical
retry_on Stripe::APIConnectionError, wait: :exponentially_longer, attempts: 5
discard_on Stripe::InvalidRequestError
def perform(args)
raise ArgumentError, 'Hash expected' unless args.is_a?(Hash)
args = args.deep_symbolize_keys
payment_id = args.fetch(:payment_id)
reason = args.fetch(:reason, 'customer_request')
payment = Payment.find(payment_id)
return if payment.refunded? # Idempotencia
# ... lógica de refund
rescue => e
ErrorTracker.notify(e, payment_id: payment_id)
raise
end
end
```
### 4.6 Seguridad y Autorización
```
✅ Endpoints tienen autorización apropiada (CanCanCan, Pundit)
✅ No se exponen IDs de DB en APIs (usar UUIDs o secure_ids)
✅ Datos sensibles están encriptados (attr_encrypted)
✅ SQL injection prevenido (usar placeholders, no string interpolation)
✅ XSS prevenido (sanitize inputs)
✅ CSRF tokens en formularios
**Ejemplo de autorización correcta:**
# app/controllers/api/v1/pricing_rules_controller.rb
class Api::V1::PricingRulesController < ApiController
load_and_authorize_resource # CanCanCan
def update
# authorize! ya fue ejecutado por load_and_authorize_resource
if @pricing_rule.update(pricing_rule_params)
render json: @pricing_rule
else
render json: { errors: @pricing_rule.errors }, status: :unprocessable_entity
end
end
private
def pricing_rule_params
params.require(:pricing_rule).permit(:age_min, :age_max, :price_cents)
end
end
# app/models/ability.rb
class Ability
include CanCan::Ability
def initialize(user)
return unless user.present?
if user.admin?
can :manage, PricingRule
elsif user.facility_manager?
can :manage, PricingRule, facility_id: user.facility_id
else
can :read, PricingRule
end
end
end
```
### 4.7 CI/CD Checks Pasando
```
✅ RuboCop sin warnings
✅ Brakeman sin vulnerabilidades nuevas
✅ Tests en CI pasando (no solo local)
✅ Coverage no disminuyó
✅ Build artifacts generados correctamente
✅ Docker image builds (si aplica)
**Validación local antes de push:**
bundle exec rails ci # Ejecuta todos los checks
bundle exec brakeman -z # Security scan
bundle exec pronto run -c develop # Code review automatizado
```
### 4.8 Migraciones de Base de Datos
```
✅ Migraciones son reversibles (método down implementado)
✅ Migraciones de datos si es necesario (backfill)
✅ Probadas en staging antes de prod
✅ Indexes apropiados para queries nuevas
✅ Compatible con zero-downtime deployment
✅ Considera volumen de datos en producción
**Ejemplo de migración reversible:**
class UpdateAgeRangesBounds < ActiveRecord::Migration[6.1]
def up
# Actualizar rangos 18-65 a 18-64
PricingRule.where(age_min: 18, age_max: 65).find_each do |rule|
rule.update_columns(age_max: 64, updated_at: Time.current)
end
end
def down
# Revertir cambios
PricingRule.where(age_min: 18, age_max: 64).find_each do |rule|
rule.update_columns(age_max: 65, updated_at: Time.current)
end
end
end
```
### 4.9 Documentación Actualizada
```
✅ Comentarios en código complejo explicando el "por qué"
✅ Métodos públicos documentados (YARD, JSDoc)
✅ GraphQL schema tiene descriptions
✅ README actualizado si hay nuevos setup steps
✅ Variables de entorno documentadas (.env.example)
✅ API docs actualizados (Swagger/OpenAPI)
✅ Cambios arquitectónicos documentados en /docs
**Ejemplo de documentación clara:**
# app/services/pricing_calculator.rb
# Calcula el precio de una reserva considerando:
# - Edad del usuario (aplica descuentos por grupo etario)
# - Horario del turno (peak vs off-peak)
# - Membresía activa (descuentos adicionales)
# - Promociones vigentes
#
# @param user [User] Usuario que hace la reserva
# @param shift [Shift] Turno a reservar
# @return [Money] Precio final en cents
# @raise [PricingError] Si no se puede calcular precio
#
# @example
# calculator = PricingCalculator.new(user, shift)
# price = calculator.calculate
# # => #
def calculate
# ...
end
```
### 4.10 Code Review Aprobado
```
✅ PR tiene descripción clara con contexto
✅ Screenshots para cambios de UI
✅ Al menos 1 reviewer aprobó (2 para features críticos)
✅ Todos los comentarios resueltos
✅ No hay merge conflicts
✅ Branch está actualizado con develop/main
**Template de PR bien hecho:**
## 🎯 Objetivo
PLAT-2768: Corregir rangos de edad superpuestos en pricing
## 📝 Cambios
- Actualizar AgeGroupValidator para prevenir overlaps
- Cambiar rango 18-65 a 18-64 en migración
- Agregar tests para edge cases
## 🧪 Testing
- ✅ Unit tests: 12 nuevos, todos pasan
- ✅ Integration tests: Flujo completo de pricing
- ✅ Manual: Probado en staging con 5 facilities
## 📸 Screenshots
[imagen del form con validación de overlaps]
## ⚠️ Consideraciones
- Migración toma ~5min en prod (estimado)
- Ejecutar en horario de bajo tráfico
- Rollback disponible vía down migration
```
### 4.11 Performance y Queries
```
✅ No hay N+1 queries (usar includes/preload)
✅ Queries complejas optimizadas
✅ Caching donde es apropiado (Redis, Rails.cache)
✅ Background jobs para operaciones pesadas (>5 segundos)
✅ Pagination en listados grandes
**Ejemplo de prevención N+1:**
# ❌ Mal (N+1)
facilities.each do |facility|
puts facility.owner.name # Query por cada facility
end
# ✅ Bien
facilities.includes(:owner).each do |facility|
puts facility.owner.name # Una sola query
end
**Validación en Rails console:**
ActiveRecord::Base.logger = Logger.new(STDOUT)
# Ejecutar código y contar queries
```
---
## 5. Flujo de Trabajo con DoR y DoD
### El proceso ideal
```
1. Product/PM crea ticket
↓
2. Equipo revisa contra DoR en refinement
├─ ✅ Cumple DoR → Pasa a backlog "Ready"
└─ ❌ No cumple → Regresa a PM para completar
↓
3. Sprint Planning: Desarrollador toma ticket de backlog "Ready"
↓
4. Desarrollo e implementación
↓
5. Desarrollador auto-revisa DoD antes de crear PR
↓
6. Code review verifica DoD
├─ ✅ Cumple DoD → Aprobado para merge
└─ ❌ No cumple → Request changes
↓
7. Merge a develop → Auto-deploy a staging
↓
8. QA verifica en staging
↓
9. Deploy a producción
↓
10. Monitoring post-deploy (24-48h)
```
---
## 6. Adaptaciones según Contexto
### Hotfixes de Producción
**DoR simplificado:**
- Contexto: ¿Qué está roto y por qué?
- Impacto: ¿Cuántos usuarios afectados?
- Solución propuesta: ¿Cómo arreglarlo?
- Rollback plan: ¿Cómo revertir si falla?
**DoD mínimo pero NO negociable:**
- Tests (al menos el happy path)
- Code review (puede ser post-merge en casos extremos)
- Documentación (puede ser post-fix)
### Spikes de Investigación
**DoR para spikes:**
- Preguntas a responder
- Opciones a evaluar
- Criterio de decisión
- Timebox (ej: 4 horas max)
**DoD para spikes:**
- Documento con hallazgos
- Recomendación técnica
- Tickets de implementación si procede
- Actualización de arquitectura docs
### Refactors Técnicos
**DoR para refactors:**
- Justificación técnica clara (performance, mantenibilidad, etc.)
- Métricas actuales (ej: coverage 60%, tiempo de CI 15min)
- Métricas objetivo (ej: coverage 80%, tiempo de CI 8min)
**DoD para refactors:**
- Comportamiento NO cambió (tests originales siguen pasando)
- Nuevos tests agregados si hay nueva lógica
- Métricas objetivo alcanzadas
- Documentación de cambios arquitectónicos
---
## 7. Señales de Alerta
### DoR insuficiente (síntomas):
* Desarrolladores haciendo > 5 preguntas por ticket durante desarrollo
* Historias bloqueadas por dependencias no identificadas
* Estimaciones erradas por factor de 2x o más
* Retrabajo frecuente por malentendidos
* Desarrolladores rechazando tickets del backlog
### DoD no seguido (síntomas):
* Bugs en features recién desplegadas (< 48h)
* Code reviews que toman > 1 día
* Tests skippeados o pendientes en develop
* Deuda técnica creciendo sprint tras sprint
* Rollbacks frecuentes en producción
* Coverage decreciendo consistentemente
---
## 8. Caso Real Completo
### Historia: Corregir rangos de edad superpuestos
**DoR Checklist (Pre-desarrollo):**
```
✅ Contexto: Rangos 18-65 y 65-100 causan precios duplicados
✅ Impacto: 150 usuarios/mes, descuadre en reportes
✅ Criterios aceptación: Cambiar a 18-64, validar no-overlap
✅ Alcance técnico:
- Backend: PricingRule model, AgeGroupValidator
- Migración: UpdateAgeRangeBounds
- Tests: Unit + integration
✅ Multi-tenancy: Por facility, 45 facilities afectadas
✅ Seguridad: Solo admins, auditoría en logs
✅ Testing plan: Definido (ver arriba)
✅ Documentación: Actualizar validator docs
✅ Dependencias: Ninguna
✅ Estimación: 5 story points (1-2 días)
```
**Desarrollo (2 días)**
Día 1:
- Actualizar AgeGroupValidator con lógica no-overlap
- Crear migración UpdateAgeRangeBounds
- Tests unitarios (12 specs nuevos)
Día 2:
- Tests de integración (flujo completo pricing)
- Probar migración en staging
- Documentar cambios
- Code review self-check
**DoD Checklist (Pre-PR):**
```
✅ Código: Validaciones implementadas, migración creada
✅ Tests: 15 specs nuevos, coverage +2%, todos pasan
✅ RuboCop: 0 warnings
✅ Brakeman: 0 issues nuevos
✅ Migraciones: Reversible, probada en staging
✅ Performance: Sin queries adicionales, usa índices existentes
✅ Documentación: Comentarios en validator, migración documentada
✅ PR: Descripción completa, screenshots de admin UI
✅ CI: Todos los checks en verde
✅ QA: Probado en staging con 5 facilities reales
```
**Code Review (1 día)**
Comentarios:
- "Agregar test para edad = null" → Agregado
- "Migración podría ser lenta en prod" → Agregada nota en PR
- "Falta docs en GraphQL schema" → Agregado
**Resultado:**
- Merge exitoso
- Deploy a producción sin issues
- 0 bugs reportados post-deploy
- Tiempo total: 3 días (según estimación)
---
## 9. Implementando DoR/DoD en tu Equipo
### Paso 1: Empezar simple
No implementes TODO de una vez. Empieza con lo básico:
**DoR mínimo viable:**
1. Título claro + número de ticket
2. Criterios de aceptación
3. Alcance técnico identificado
**DoD mínimo viable:**
1. Tests pasando
2. Code review aprobado
3. Sin linter warnings
### Paso 2: Iterar y mejorar
Cada retrospectiva:
- ¿Qué faltó en DoR que causó problemas?
- ¿Qué en DoD no se cumplió y causó bugs?
- Agregar esos puntos al checklist
### Paso 3: Automatizar
```bash
# pre-commit hook para DoD
#!/bin/bash
bundle exec rubocop || exit 1
bundle exec rspec || exit 1
echo "✅ DoD checks passed"
```
### Paso 4: Medir impacto
Métricas a trackear:
- Tiempo promedio de desarrollo por story point (debe bajar)
- Bugs en producción post-deploy (debe bajar)
- Tickets regresados por falta de información (debe bajar)
- Velocity del equipo (debe subir o estabilizarse)
---
## 10. Reflexión Final
DoR y DoD no son burocracia. Son **contratos** que protegen a todos:
**Para Desarrolladores:**
- Claridad antes de empezar
- Confianza al hacer merge
- Menos interrupciones
**Para Product/PM:**
- Expectativas alineadas
- Menos sorpresas
- Features realmente terminados
**Para el Negocio:**
- Menos bugs en producción
- Entregas predecibles
- ROI medible
Después de años implementando DoR/DoD en múltiples equipos, puedo afirmar:
> Los equipos con DoR/DoD claro son 2-3x más rápidos que equipos sin ellos. No porque trabajen más rápido, sino porque **no pierden tiempo en retrabajo, bugs y malentendidos**.
La inversión inicial de definir estos checklists se paga en la primera semana.
---
## Recursos para Profundizar
**Plantillas descargables:**
- DoR Template (Notion/Confluence/Jira)
- DoD Checklist (GitHub PR template)
- Code Review Checklist
**Herramientas recomendadas:**
- Danger.js - Automatizar code review checks
- Pronto - Code review automatizado
- SimpleCov - Coverage tracking
- Brakeman - Security scanning
**Lecturas recomendadas:**
- "User Stories Applied" - Mike Cohn
- "The DevOps Handbook" - Gene Kim
- "Accelerate" - Nicole Forsgren
---
**¿Tu equipo tiene DoR y DoD claros? ¿Qué otros criterios agregarías? Comparte tu experiencia en los comentarios.**
*Escrito desde la trinchera del desarrollo ágil, con café y muchos sprints de experiencia.*
================================================================================
## Post: 2025-10-10-guardia-del-sprint-triage-engineer
Source file: _posts/2025-10-10-guardia-del-sprint-triage-engineer.md
================================================================================
---
layout: post
title: Guardia del Sprint - el escudo invisible del equipo de desarrollo
modified:
categories: Agile, DevOps, Engineering
excerpt: >
El rol que protege al equipo, estabiliza el producto y mantiene la cordura en medio del caos
tags: []
image:
feature:
date: 2025-10-10T08:12:53-07:00
---
## Introducción: Cuando el mundo arde y alguien tiene que sostener el fuego
En un equipo de desarrollo ágil, siempre hay una persona que detiene el fuego mientras el resto sigue construyendo.
Esa persona eres tú. O lo serás pronto.
En mis más de 10 años como ingeniero de software, he sido guardia del sprint decenas de veces, y también he liderado equipos donde implementamos este rol de forma estructurada. No es el trabajo más glamoroso, pero es **el más crítico para la estabilidad del producto y la salud mental del equipo**.
> ✅ *El guardia del sprint no apaga incendios: los previene, los canaliza y documenta para que no vuelvan a ocurrir.*
Este artículo es una guía práctica, honesta y técnica sobre qué es ser guardia del sprint (o **triage engineer**), por qué importa tanto, y cómo implementarlo sin morir en el intento.
---
## 1. ¿Qué diablos es un Guardia del Sprint?
Déjame ser claro desde el inicio:
**El guardia del sprint es la persona designada para atender incidentes, errores y bugs de baja/media complejidad durante un periodo determinado (generalmente una semana o un sprint completo), garantizando la continuidad operativa del sistema y la eficiencia del equipo.**
En otras palabras:
* 🚨 **Eres el firewall humano** que intercepta interrupciones antes de que lleguen al resto del equipo
* 🔍 **Clasificas, priorizas y atiendes** reportes de producción
* 🩹 **Resuelves lo urgente** sin romper el flujo del sprint
* 📋 **Documentas y escala** lo que requiere más trabajo
---
## 2. ¿Por qué necesitas este rol?
Si alguna vez has estado en un sprint donde:
* El equipo es interrumpido 15 veces al día por bugs menores
* Los reportes de producción quedan sin atender durante días
* Nadie sabe quién debe responder al mensaje de "el pago falló"
* El tech lead está debuggeando en producción mientras debería estar en planning
**Necesitas un guardia del sprint.**
Este rol existe para resolver problemas estructurales:
| Problema | Solución con Guardia |
|----------|---------------------|
| Interrupciones constantes | El guardia absorbe todas las alertas |
| Bugs sin priorizar | Clasifica (triage) según urgencia |
| Tiempo de resolución alto | Respuesta inmediata a incidentes |
| Caos en producción | Un solo punto de contacto claro |
| Sprint con scope creep | El backlog del sprint se protege |
---
## 3. Responsabilidades del Guardia (lo que realmente haces)
Déjame ser específico, porque este rol no es solo "estar disponible":
### Incidentes en producción
* Monitorear dashboards (Datadog, New Relic, Sentry, Honeybadger)
* Responder a alertas críticas en menos de 5 minutos
* Analizar logs y tracebacks
* Ejecutar rollbacks temporales si es necesario
* Coordinar con DevOps/SRE para problemas de infra
**Ejemplo real:**
```ruby
# Detectas un timeout en Stripe Webhooks
# Logs revelan que un job de Sidekiq está bloqueando la cola
# Acción inmediata:
SomeHeavyJob.cancel_all # Liberas la cola
Bugsnag.notify("Stripe webhooks blocked by job X") # Notificas
# Creas ticket en Jira para refactorizar el job
```
### Bugs simples (1-3 horas)
* Correcciones menores que no requieren diseño
* Typos en mensajes, validaciones faltantes
* Problemas de permisos o configuración
**Ejemplo:**
```javascript
// Usuario reporta: "No puedo editar mi perfil"
// El guardia detecta:
if (user.role !== 'admin') { // ❌ Lógica incorrecta
return false
}
// Fix en 20 minutos:
if (!user.can_edit_profile) { // ✅ Usa permisos reales
return false
}
```
### Soporte interno
* Responder dudas técnicas del equipo de soporte
* Ayudar a QA a reproducir bugs complejos
* Validar configuraciones con producto
### Mantenimiento menor
* Limpiar jobs fallidos en Sidekiq/Resque
* Reiniciar workers bloqueados
* Revisar métricas y uso de recursos
* Verificar que los cronjobs estén corriendo
### Documentación crítica
* Registrar cada incidente en Jira/Linear/Notion
* Crear runbooks para problemas recurrentes
* Actualizar el wiki técnico con lecciones aprendidas
---
## 4. Duración y Rotación del Rol
La duración y rotación del guardia **depende completamente del equipo y la cultura de la empresa**. No hay una regla única, pero estas son las modalidades más comunes:
### Rotación Semanal (la más común)
* **Lunes a viernes:** Una persona es guardia
* **Siguiente semana:** Rota a otro miembro del equipo
* **Ventaja:** Nadie se quema, el conocimiento se distribuye rápidamente
### Rotación por Sprint Completo
* Una persona toma el rol durante todo el sprint (1-2 semanas)
* **Ventaja:** Mayor continuidad en el seguimiento de incidentes
* **Desventaja:** Puede ser más agotador para quien lo hace
### Rotación Diaria
* Equipos grandes rotan día a día
* **Ventaja:** Menor carga individual
* **Desventaja:** Menos continuidad en el seguimiento
### Rotación por Tamaño de Equipo
* **Equipos pequeños (2-4 devs):** Por sprint completo
* **Equipos medianos (5-8 devs):** Semanal
* **Equipos grandes (9+ devs):** Pueden rotar cada 2-3 días o tener dos guardias simultáneos
**Ventajas de rotar (independiente del periodo):**
* Todo el equipo conoce el sistema end-to-end
* Se comparte el conocimiento de producción
* Nadie se quema haciendo solo esto
* Fortalece la empatía y responsabilidad compartida
**Pro tip:** Si tu equipo tiene on-call 24/7, combina este rol con guardias fuera de horario (pagadas y rotativas).
---
## 5. Soft Skills: Lo que realmente te hace un buen Guardia
Ser guardia del sprint **no es solo técnica**. De hecho, las soft skills pueden ser más importantes que saber debuggear. Aquí están las habilidades clave:
### Comunicación clara y proactiva
**Lo que NO debes hacer:**
```
❌ "No sé qué pasa, lo veo después"
❌ *Silencio por 2 horas mientras investigas*
❌ "Está roto, no tengo idea de cómo arreglarlo"
```
**Lo que SÍ debes hacer:**
```
✅ "Recibido, estoy investigando. Les actualizo en 15 minutos"
✅ "Reproduje el bug. Voy a revisar los logs de Stripe"
✅ "Este flujo es complejo, voy a pedir ayuda a @juan que lo implementó"
```
### Saber pedir ayuda (sin miedo ni ego)
**Cuándo pedir ayuda:**
* Después de 20-30 minutos sin avance claro
* Cuando el incidente es crítico y no tienes contexto
* Cuando involucra un flujo que nunca has tocado
* Cuando la solución requiere decisiones de arquitectura
**Cómo pedir ayuda correctamente:**
**❌ MAL:**
```
"@tech-lead ayuda, esto no funciona"
```
**✅ BIEN:**
```
"@juan necesito ayuda con el flujo de pagos 3DS
Contexto:
- Usuario no puede completar pago con Visa
- Error: 'authentication_required' desde Stripe
- Ya revisé: logs, webhook handler, job de confirmación
Lo que intenté:
1. Reinicié el job manualmente → mismo error
2. Probé con otra tarjeta → funciona
3. Revisé docs de Stripe → menciona 3DS v2
¿Podrías revisar si el flujo 3DS está configurado
correctamente para tarjetas europeas?"
```
### Coordinación con otros equipos
**Con Operaciones/Soporte:**
* Mantén comunicación bidireccional constante
* Actualiza el estado del ticket cada 30-60 minutos
* Explica en lenguaje simple, sin jerga técnica excesiva
* Anticipa preguntas: "¿Cuándo estará resuelto?" → "Estimo 1 hora más"
**Ejemplo de actualización a soporte:**
```
#support-channel
@soporte-team Update sobre ticket #12345
✅ Identificamos la causa: timeout en gateway de pagos
🚧 Solución en progreso: ajustando timeout de 30s → 60s
⏱️ ETA: Deploy en 20 minutos
📋 Workaround temporal: Pedir al usuario que reintente
Les aviso cuando esté resuelto.
```
**Con el equipo técnico:**
* No interrumpas a todos, identifica al experto del módulo
* Usa hilos/threads en Slack para no contaminar canales
* Documenta lo que aprendiste para la próxima rotación
### Empatía bajo presión
**Recuerda:**
* El usuario final está frustrado, no enojado contigo
* Soporte está presionado por el cliente, no te está atacando
* Tu equipo confía en ti, no espera que seas perfecto
**Frases que ayudan:**
* "Entiendo la urgencia, estoy en esto"
* "Gracias por el reporte detallado, me ayuda mucho"
* "Buen catch, no había visto ese edge case"
### Documentar mientras resuelves
Un buen guardia deja rastro para el futuro. Ejemplo de post-mortem rápido (5 minutos después de resolver):
**Post-mortem: Timeout en pagos con Visa 3DS**
- **Fecha:** 2025-10-10 15:30 UTC
- **Duración:** 45 minutos
- **Impacto:** 8 usuarios afectados
**Root cause:**
Timeout configurado en 30s, pero bancos europeos tardan ~45s en responder el challenge 3DS.
**Solución aplicada:**
- Aumenté timeout a 60s en `payment_service.rb:89`
- Deploy a producción en 20 minutos
- Verificado con usuario afectado
**Aprendizajes:**
- Documentar timeouts específicos por región
- Crear alerta si 3DS tarda >40s
- Agregar retry automático para timeouts
**Próximos pasos:**
- [ ] Crear ticket para refactorizar configuración de timeouts
- [ ] Agregar tests para este edge case
### Gestión del estrés y autoconocimiento
**Tips prácticos:**
* Si llevas 2 horas sin resolver algo crítico → **Escala, no te quemes**
* Toma breaks de 5 minutos cada hora, aunque estés en medio de un incidente
* No te lleves trabajo mental fuera del horario de guardia
* Pide feedback después de tu semana: "¿Qué puedo mejorar?"
**Señales de que debes escalar:**
* Sientes pánico o bloqueo mental
* El incidente supera tu nivel de conocimiento técnico
* Han pasado 30+ minutos sin avance en un crítico
* Necesitas tomar una decisión de arquitectura importante
---
## 6. Beneficios Reales (no es solo sufrimiento)
Sé que ser guardia puede sonar agotador, pero cuando lo implementas bien:
✅ **El equipo puede concentrarse** en completar el sprint sin interrupciones
✅ **Los incidentes se resuelven más rápido** (de horas a minutos)
✅ **Mejora la satisfacción del cliente** porque los bugs se atienden inmediatamente
✅ **Se fortalece la cultura de ownership** compartido
✅ **Se documenta mejor** porque el guardia tiene tiempo para escribir
En proyectos anteriores donde implementé este rol:
* ⬇️ **MTTR bajó de 4 horas a 45 minutos**
* ⬆️ **Sprint completion rate subió del 65% al 85%**
* 📈 **Customer satisfaction aumentó 20 puntos**
---
## 6. Buenas Prácticas para No Morir en el Intento
Después de años haciendo esto, aprendí qué funciona y qué no:
### 1. Canal dedicado y estructura de requests
Los requests del guardia pueden llegar por diferentes canales, **dependiendo de las herramientas que use tu empresa**:
**Canales comunes:**
* **Slack/Teams:** Canal dedicado como `#oncall-incidents` o `#guardia-sprint`
* **Jira/Linear:** Tickets con label `[GUARDIA]` o `[TRIAGE]`
* **PagerDuty/Opsgenie:** Para incidentes críticos de producción
* **Email:** Para reportes de clientes o soporte (menos común)
**Estructura de un Request bien formado:**
Todo request debe contener esta información mínima para ser atendido eficientemente:
**📋 Template de Request para Guardia**
- **Título:** [PROD] Timeout en checkout de pagos
- **Prioridad:** 🔴 Critical / 🟠 High / 🟡 Medium / 🟢 Low
**Descripción:**
Usuario no puede completar el pago. Al hacer clic en "Pagar", la página se queda cargando indefinidamente.
**Flujo de Reproducción:**
1. Ir a https://app.ejemplo.com/checkout
2. Seleccionar método de pago "Tarjeta de crédito"
3. Ingresar datos: 4242 4242 4242 4242
4. Click en "Pagar"
5. ❌ Error: La página se queda en loading
**Logs/Screenshots/Video:**
- Video: https://loom.com/share/abc123
- Screenshot del console: [adjunto]
- Error en logs: "Stripe timeout after 30s"
**Usuario afectado:**
- Email: cliente@ejemplo.com
- ID: 12345
- Browser: Chrome 120 / MacOS
**Reportado por:** @soporte-team
**Fecha/Hora:** 2025-10-10 14:30 UTC
**Ejemplo en Slack:**
```
#oncall-incidents
@guardia 🔴 URGENT
**Título:** Payment gateway down - Stripe webhooks failing
**Descripción:**
Últimos 50 webhooks de Stripe están fallando.
Pagos se procesan pero no se confirman en el sistema.
**Logs:**
https://datadog.com/logs?query=stripe+webhook+500
**Impacto:**
~20 usuarios afectados en últimos 15 minutos
**Acción inmediata sugerida:**
Revisar Sidekiq queue y status de workers
```
**Ejemplo en Jira:**
| Campo | Valor |
|-------|-------|
| **Tipo** | Bug - Guardia |
| **Prioridad** | High |
| **Labels** | [GUARDIA], [PROD], [PAYMENTS] |
| **Título** | Usuario no puede editar perfil |
| **Descripción** | Ver template arriba |
| **Attachments** | video.mp4, screenshot.png, logs.txt |
| **Asignado a** | Guardia actual (rotar automáticamente) |
### 2. Tablero de triage con prioridades y estados
**Todo request debe tener dos dimensiones: Prioridad y Estado.**
**Prioridades y SLAs:**
| Prioridad | SLA | Acción |
|-----------|-----|--------|
| 🔴 Critical | < 15 min | Escala inmediatamente |
| 🟠 High | < 2 horas | Resuelve en el día |
| 🟡 Medium | < 1 día | Agenda para próximos días |
| 🟢 Low | Backlog | Envía a sprint planning |
**Estados del ciclo de vida:**
| Estado | Descripción | Quién lo actualiza |
|--------|-------------|-------------------|
| **📥 To Do** | Request recibido, pendiente de revisión | Sistema/Reporter |
| **🔍 Investigating** | Guardia está analizando logs, reproduciendo el bug | Guardia |
| **🚧 In Progress** | Solución en desarrollo o aplicándose | Guardia |
| **⏸️ Blocked** | Requiere información adicional o depende de otro equipo | Guardia |
| **✅ Done** | Resuelto y verificado en producción | Guardia |
| **📋 Backlog** | No urgente, se agenda para próximo sprint | Guardia/Tech Lead |
| **🔄 Escalated** | Requiere intervención del tech lead o equipo completo | Guardia |
**Ejemplo de flujo completo en Jira:**
1. Soporte crea ticket → Estado: 📥 To Do
2. Guardia lo toma → Estado: 🔍 Investigating
3. Reproducido, inicia fix → Estado: 🚧 In Progress
4. Necesita info del usuario → Estado: ⏸️ Blocked
5. Info recibida, continúa → Estado: 🚧 In Progress
6. Fix deployado y verificado → Estado: ✅ Done
**Pro tip:** Configura un dashboard tipo Kanban con estas columnas para visualizar el estado en tiempo real.
### 3. Automatiza alertas
```yaml
# datadog-monitors.yml
monitors:
- name: "Stripe Webhook Failures"
query: "sum(last_5m):sum:stripe.webhook.failed > 10"
message: "@slack-#oncall URGENT: Stripe webhooks failing"
- name: "Sidekiq Queue Blocked"
query: "avg(last_10m):avg:sidekiq.queue_latency > 300"
message: "@pagerduty High latency detected"
```
### 4. Retrospectiva de incidentes
Cada semana, en la retro del sprint:
* ¿Cuántos incidentes hubo?
* ¿Cuáles fueron recurrentes?
* ¿Qué podemos automatizar o prevenir?
* ¿El guardia tuvo suficiente soporte?
---
## 7. Caso Real: Una Semana como Guardia del Sprint
**Lunes 9:00 AM**
* Recibo el pase de guardia del compañero anterior
* Reviso el dashboard: 3 alertas menores del fin de semana
* Clasifico y creo tickets
**Martes 2:30 PM**
* 🚨 Alerta crítica: Payment gateway timeout en Stripe
* Analizo logs → Job bloqueando Sidekiq
* Cancelo el job, libero cola, notififico
* Tiempo total: 18 minutos
**Miércoles 11:00 AM**
* Soporte reporta: "Usuario no puede reservar canchas"
* Reproduzco el bug → validación incorrecta
* Fix en 25 minutos, deploy a producción
**Jueves**
* Día tranquilo, actualizo runbooks
* Limpio jobs fallidos del mes anterior
* Reviso métricas de uso
**Viernes 4:00 PM**
* Hago handoff al siguiente guardia
* Comparto aprendizajes de la semana
* 📊 Resultado: 12 incidentes atendidos, 8 bugs resueltos, 0 escalaciones
---
## 8. Reflexión Final
Ser guardia del sprint no es solo "apagar incendios". Es cuidar la salud del producto, proteger el tiempo del equipo y asegurar que los usuarios sigan confiando en la plataforma.
Es un rol de **responsabilidad**, **empatía** y **técnica**.
Si tu equipo todavía no tiene este rol implementado, te invito a probarlo. Empieza con una semana, rota entre 2-3 personas, y mide el impacto.
Te garantizo que en un mes, no querrán volver a trabajar sin un guardia del sprint.
---
**¿Has sido guardia del sprint? ¿Qué estrategias te funcionaron mejor? Déjame saber en los comentarios o contáctame directamente.**
*Escrito desde la trinchera, con café y mucho cariño técnico.*
================================================================================
## Post: 2026-05-07-ADRs-en-sistemas-de-pagos
Source file: _posts/2026-05-07-ADRs-en-sistemas-de-pagos.md
================================================================================
---
layout: post
title: ADRs en sistemas de pagos - por qué documentar decisiones te salva de auditorías, incidentes y reescrituras
modified:
categories: Architecture, Payments, Documentation
excerpt: >
Por qué los Architecture Decision Records son innegociables cuando manejas dinero, compliance y proveedores externos.
tags: []
image:
feature:
date: 2026-05-07T09:00:00-07:00
---
## Introducción: "¿Por qué hicimos esto así?"
Imagínate esta escena: estás en una reunión de incidentes. Producción está cayéndose porque un gateway de pagos respondió con un timeout y el sistema reintentó la transacción tres veces. Resultado: el cliente fue cobrado tres veces.
Alguien pregunta lo inevitable:
> *"¿Por qué reintentamos tres veces sin idempotency key? ¿Quién decidió esto?"*
Silencio incómodo. El que tomó la decisión ya no trabaja en la empresa. El commit dice *"add retry logic"* y no hay más contexto. Nadie sabe si fue una decisión deliberada, un workaround temporal, o simplemente algo que se copió de un tutorial.
Esto, queridos lectores, es exactamente el problema que los **ADRs (Architecture Decision Records)** vienen a resolver. Y en sistemas de pagos, **no tenerlos es jugar a la ruleta con el dinero del negocio**.
En este artículo te explico qué son, por qué en payments son críticos, qué decisiones siempre deberías documentar, y cómo no caer en los errores típicos.
---
## 1. ¿Qué es un ADR (y por qué no es solo "documentación más")?
Un ADR es un documento corto que captura **una decisión arquitectónica importante** junto con su **contexto** y sus **consecuencias**.
La estructura mínima es brutal de simple:
* **Título** — qué se decidió.
* **Estado** — propuesto, aceptado, deprecado, superseded.
* **Contexto** — qué problema o restricción motivó la decisión.
* **Decisión** — qué se eligió hacer.
* **Consecuencias** — qué ganamos y qué perdemos.
> ✅ *La wiki documenta el **qué**. El ADR documenta el **porqué**.*
Esa diferencia es la que cambia todo. Un nuevo dev puede leer el código y entender qué hace. Pero solo un ADR le dice **por qué se hizo así y qué alternativas se descartaron**.
---
## 2. ¿Por qué los sistemas de pagos son un caso especial?
He trabajado con sistemas de logística, e-commerce, reservas y pagos. Te lo digo con honestidad: **payments es donde más caro pagas la falta de ADRs**. Y aquí está el porqué:
* 💰 **El costo de equivocarse se mide en dinero real.** Un retry mal implementado es un chargeback. Un webhook mal documentado es una transacción perdida. No es un bug cosmético, es revenue.
* 🔒 **El compliance manda.** PCI-DSS, SCA (Strong Customer Authentication), PSD2, 3DS v2. Los auditores **te van a preguntar por qué tu sistema hace X**, y "porque sí" no es una respuesta válida.
* 🔌 **Dependes de terceros.** Stripe, PayPal, Adyen, Braintree. Cuando ellos cambian su API, tú tienes que reaccionar. Si no documentaste por qué elegiste un flow en particular, **vas a estar reverse-engineering tus propias decisiones**.
* ⏳ **Las decisiones envejecen rápido.** Lo que era óptimo hace dos años hoy es deuda técnica. Sin ADRs, no sabes qué decisiones revisar.
---
## 3. Las 5 decisiones que SIEMPRE deberías documentar como ADR
No todo merece un ADR. Pero en payments, estas cinco categorías son innegociables:
### 3.1 Elección y estrategia de payment gateway
¿Single gateway o multi-gateway? ¿Por qué Stripe sobre Adyen para ese mercado? ¿Qué criterios pesaron — fees, cobertura geográfica, soporte 3DS, time-to-market?
### 3.2 Estrategia de reintentos e idempotencia
¿Cuántos reintentos? ¿Con qué backoff? ¿Cómo se garantiza idempotencia? Este ADR solo te puede salvar de un incidente como el de la introducción.
### 3.3 Manejo de 3DS / SCA
¿Qué flow se usa — challenge obligatorio, frictionless, fallback? ¿Qué exenciones aplican (low-value, trusted beneficiary)? Aquí el compliance se mezcla con UX, y las decisiones son polémicas.
### 3.4 Tokenización y almacenamiento de datos sensibles
¿Vault propio o del provider? ¿Qué scope de PCI te queda (SAQ-A vs SAQ-D)? Esta decisión define **literalmente qué tan caro es tu compliance anual**.
### 3.5 Webhooks y reconciliación
¿Entrega garantizada o eventual consistency? ¿Cómo se manejan los duplicados? ¿Hay reconciliación batch además del stream de eventos? Aquí es donde la realidad de los sistemas distribuidos te golpea más fuerte.
---
## 4. Anatomía de un ADR real (ejemplo)
Veamos cómo se vería un ADR concreto para el caso de la introducción:
```markdown
# ADR-007: Adoptar idempotency keys en todas las llamadas a gateways
## Estado
Aceptado — 2026-03-15
## Contexto
El 12 de marzo tuvimos un incidente: un timeout en el gateway X
disparó el retry automático de nuestro cliente HTTP. La transacción
se procesó tres veces. Impacto: 47 clientes cobrados duplicado,
~USD 8.200 en refunds y soporte.
Las llamadas actuales no envían un identificador único que permita
al gateway deduplicar.
## Decisión
Todas las llamadas a gateways de pago deberán incluir un header
`Idempotency-Key` con un UUID v4 generado en el momento de crear
la intención de pago, no en el momento del retry.
La clave se persiste en la tabla `payment_attempts` y se reutiliza
en todos los reintentos del mismo intento de pago.
## Consecuencias
+ Eliminamos cobros duplicados por reintentos.
+ Cumplimos con la recomendación oficial de Stripe y Adyen.
- Requiere migración de los servicios existentes (ver ADR-008).
- Aumenta ligeramente el tamaño de la tabla `payment_attempts`.
## Alternativas consideradas
- Deshabilitar reintentos automáticos: rechazada, degrada UX.
- Locks distribuidos: rechazada, complejidad operativa innecesaria.
```
¿Ves? **Corto, contextual, accionable.** Cualquier dev que llegue en seis meses entiende qué pasó, por qué se hizo así, y qué no se debe romper.
---
## 5. Errores comunes al escribir ADRs en payments
Después de ver decenas de ADRs (algunos míos, algunos heredados), estos son los errores más frecuentes:
* ❌ **Escribirlos después del incidente.** El ADR debería ser parte del proceso de decisión, no el postmortem. Si lo escribes después, es un *Incident Report* con otro nombre.
* ❌ **Escribir novelas de 20 páginas.** Si un ADR no se lee en 5 minutos, nadie lo va a leer. Punto.
* ❌ **No marcar como *superseded*.** Cuando una decisión cambia, el ADR viejo debe quedar marcado y enlazar al nuevo. De lo contrario, conviven dos verdades.
* ❌ **Mezclar ADR con runbook o spec de producto.** El ADR no explica *cómo operar* el sistema ni *qué funcionalidad* tiene. Solo *por qué se decidió* así.
* ❌ **No referenciarlos desde el código o los PRs.** Un ADR que nadie linkea es un ADR que nadie encuentra.
---
## 6. ¿Dónde viven los ADRs?
Mi recomendación, simple y probada:
1. **Carpeta `/docs/adr/` en el mismo repo.** Numeración secuencial: `0001-payment-gateway-selection.md`, `0002-retry-strategy.md`, etc.
2. **Referenciados desde los PRs.** Toda decisión arquitectónica nueva debe linkear al ADR correspondiente.
3. **Vinculados a la documentación de alto nivel.** Si tienes documentación en capas (executive, approach, detail), los ADRs son la capa más profunda — donde viven las decisiones reales.
4. **Indexados en un README** dentro de la carpeta, con título, estado y fecha.
No necesitas Confluence, no necesitas Notion. **Markdown plano, versionado con el código, revisable por PR.** Esa es la magia.
---
## Conclusión: Los ADRs no son burocracia, son seguros de vida
He visto equipos que evitaban los ADRs porque "no tenemos tiempo". Y luego he visto a esos mismos equipos perder **semanas** intentando entender por qué un sistema de pagos hace lo que hace, en medio de una auditoría PCI o de un cambio de gateway.
Los ADRs te protegen:
* Ante **auditorías de compliance** — puedes mostrar el *porqué* de cada decisión.
* Ante **el onboarding de nuevos devs** — dejan de hacer las mismas preguntas una y otra vez.
* Ante **ti mismo en seis meses** — porque sí, vas a olvidar por qué hiciste eso.
En sistemas de pagos, donde cada decisión toca dinero, compliance y proveedores externos, los ADRs no son un *nice-to-have*. Son **infraestructura para que tu arquitectura sobreviva al tiempo**.
> *Si vas a tomar una decisión que en seis meses alguien va a cuestionar — y en payments **todas** lo son — escríbela como ADR. Tu yo futuro te lo va a agradecer.*
---
*En el próximo post de esta serie hablaremos de cómo comunicar arquitectura de payments a stakeholders no técnicos — el arte de pasar de diagramas a decisiones.*
================================================================================
## Post: 2026-06-01-Arquitectura-Base-Sistema-Pagos-Multi-Gateway
Source file: _posts/2026-06-01-Arquitectura-Base-Sistema-Pagos-Multi-Gateway.md
================================================================================
---
layout: post
title: Arquitectura base de un sistema de pagos multi-gateway - capas, patrones, comunicación y estrategias que aprendí en años de payments
modified:
categories: Architecture, Payments, Software Design, Patterns
excerpt: >
Una guía completa — desde las capas del dominio hasta los WebSockets y listeners — sobre cómo diseño sistemas de pagos que soportan múltiples pasarelas sin volverse inmantenibles.
tags: []
image:
feature:
date: 2026-06-01T10:00:00-07:00
---
## Introducción: por qué casi todos los sistemas de pagos terminan siendo un infierno
Llevo varios años trabajando con sistemas de pagos. He integrado más de 15 pasarelas distintas — Stripe, PayPal, Adyen, CardConnect, Xendit, Razorpay, BAC, OnePay, PixelPay y un largo etcétera. Y si algo aprendí es esto:
> *Casi nadie diseña la arquitectura de un sistema de pagos antes de necesitarla. Se va añadiendo un gateway, luego otro, luego otro, hasta que el código se vuelve inmantenible.*
El patrón que veo repetirse en empresa tras empresa es siempre el mismo: el primer gateway se integra "rápido y sucio" porque hay que salir a producción. El segundo se copia del primero. El tercero ya empieza a tener sus condicionales especiales. Y para el quinto, agregar un gateway nuevo es un proyecto de **3 meses** que toca 15 archivos distintos.
Yo mismo viví eso. Y tras varias rondas de refactor — algunos exitosos, otros que tuve que rehacer — fui consolidando un blueprint mental de cómo debería diseñarse un sistema de pagos multi-gateway desde el día uno. Este post es ese blueprint.
No es una receta universal. Es **lo que yo haría si arrancara hoy un sistema de pagos** que tiene que soportar múltiples pasarelas, múltiples países, múltiples métodos de pago, y crecer sin colapsar. Si llegaste tarde y ya tienes un sistema hecho un desastre, también te sirve: las últimas secciones cubren la estrategia de migración.
Está dirigido a arquitectos, tech leads y devs senior que tienen que tomar decisiones de diseño. No voy a entrar en detalles específicos de Stripe vs Adyen — voy a hablar de **conceptos generalizables** que aplican sin importar el stack, el lenguaje o la región.
Vamos.
---
# Parte I — Fundamentos
## 1. ¿Por qué multi-gateway no es opcional?
Cuando alguien me dice *"para qué tantos gateways, con uno basta"*, mi respuesta siempre incluye estos cinco puntos:
* 🌍 **Cobertura geográfica.** No existe un único PSP que cubra el mundo entero con buen pricing. Stripe es excelente en US/EU pero en Latinoamérica deja huecos. En India, RBI exige procesadores locales. En Brasil, Pix cambió las reglas del juego.
* 💸 **Tarifas competitivas.** Tener dos PSPs en paralelo te da **poder de negociación**. Le dices a Stripe "Adyen me cobra X" y de repente bajan su fee. Si solo tienes uno, estás a merced de su pricing.
* 🛡️ **Resiliencia.** Los PSPs se caen. Stripe ha tenido incidentes globales de varias horas. Si el 100% de tu revenue pasa por un solo gateway, una caída del PSP **es una caída tuya**. Con failover bien diseñado, los usuarios ni se enteran.
* 🏦 **Métodos de pago locales.** Pix en Brasil, OXXO en México, iDEAL en Holanda, UPI en India, SEPA en Europa. Cada región tiene su método preferido — y los locales suelen tener mejor conversión y menores fees que las tarjetas.
* ⚖️ **Regulación.** PSD2 + SCA en Europa, RBI en India, Open Finance en Brasil. Cada año aparecen nuevas exigencias. Estar atado a un solo PSP te deja a su ritmo de implementación.
He visto a empresas perder el equivalente a **cientos de miles de dólares** en una sola tarde por depender de un único gateway que se cayó. La pregunta no es *si* va a pasar; es *cuándo*.
---
## 2. Los 7 anti-patrones que matan a un sistema multi-gateway
Antes de hablar de cómo hacerlo bien, déjame mostrarte qué he visto repetirse en cada sistema que tuve que rescatar. Si alguno de estos te suena familiar, ya sabes por dónde empezar:
1. **God-model `Payment`.** Un único modelo de 1500+ líneas que mezcla ledger, callbacks, cobros, refunds, cuentas por cobrar, créditos, eventos y notificaciones realtime. Cualquier cambio toca a 30 personas.
2. **HTTP dentro de transacciones de base de datos.** Un `before_create` o un `transaction do ... gateway.charge ... end` mantiene locks de DB abiertos durante la llamada al PSP. Cuando Rails (o tu framework) reintenta y el PSP ya cobró → **doble cobro real**.
3. **Dispatch dinámico sin contrato.** `"#{gateway.classify}::Charge".constantize.call`. Sin capability check, sin tipado, sin observabilidad por gateway. Funciona en demo, se cae en producción.
4. **Webhooks sin disciplina.** Sin verificación de firma, sin dedupe, sin persistencia del payload crudo. He visto pagos perdidos solo porque un crash mató al worker antes de procesar el webhook.
5. **Frontend acoplado al gateway.** Un `switch (gateway)` de 13 ramas en el cliente. Agregar un gateway = tocar el front, el back, el mobile, y rezar.
6. **Procesamiento síncrono donde no debería serlo.** Bloquear al usuario 30 segundos esperando que un PSP latinoamericano responda. Spoiler: timeouts, retries del usuario, doble cobro.
7. **Una sola fuente de verdad.** Confiar 100% en el webhook. O solo en el response síncrono. O solo en el cron de reconciliation. Spoiler: las tres mienten en algún momento. **Necesitas cruzarlas**.
> *Si tu sistema actual tiene 3 o más de estos, no estás solo. Lo que sigue es cómo no caer en ellos.*
---
## 3. Arquitectura por capas — el blueprint base
La base de todo es separar responsabilidades en capas claras, donde **cada capa solo conoce la inmediatamente inferior**. Esto es lo que llamo el blueprint base — funciona en cualquier lenguaje, en cualquier framework.
```mermaid
graph TB
subgraph "Presentation"
C[Controllers / GraphQL / REST endpoints]
end
subgraph "Public API (Facade)"
F[Payments::Api]
end
subgraph "Application (Use Cases)"
UC[CreatePaymentIntent · Capture · Refund · Void · ProcessWebhook]
end
subgraph "Domain"
D[PaymentIntent · PaymentSession · PaymentTransaction · WebhookEvent]
end
subgraph "Infrastructure Adapters"
A[StripeAdapter · AdyenAdapter · LocalPSPAdapter ...]
end
subgraph "Integration / Messaging"
I[Webhooks · WebSockets · Listeners · Outbox · Pub/Sub]
end
C --> F --> UC --> D
UC --> A
UC --> I
I --> UC
```
Las **6 capas que separo siempre**:
| Capa | Responsabilidad | Lo que NO hace |
|---|---|---|
| **Presentation** | Cargar recursos, autorizar, delegar al facade, renderizar | Lógica de pricing, selección de gateway, llamadas HTTP al PSP |
| **Public API (Facade)** | Único entry point al dominio de pagos. Retorna resultados tipados | Permitir que código externo toque internals |
| **Application (Use Cases)** | Orquestar el flujo: idempotency → gateway selection → adapter call → persistir | Hablar HTTP directamente; saltarse el dominio |
| **Domain** | Entidades, state machines, invariantes financieras | Conocer HTTP, SDKs o adapters concretos |
| **Infrastructure Adapters** | Un adapter por gateway. Habla HTTP/SDK. Normaliza errores | Tocar el ledger; conocer el dominio de negocio |
| **Integration / Messaging** | Webhooks entrantes, sockets, eventos de dominio, outbox | Lógica de negocio; persistencia financiera |
La regla de oro es: **el dominio no sabe que existe Stripe. El controller no sabe que existe Adyen.** Toda la complejidad gateway-específica vive en los adapters.
---
# Parte II — Las abstracciones core
## 4. Las abstracciones del dominio que no pueden faltar
Estas son las 9 abstracciones que aparecen en todo sistema de pagos serio que he construido o auditado. Si alguna falta, hay un dolor garantizado más adelante:
* **`PaymentIntent`** — la intención de negocio. Es lo que el usuario quiere lograr: cobrar X monto por Y producto. Tiene una **state machine** explícita (`created → authorized → captured → refunded`) e invariantes financieras. Es la unidad de trabajo del dominio.
* **`PaymentTransaction`** — el log técnico **append-only**, una fila por cada llamada al PSP (authorize, capture, refund, void, tokenize). Es donde reconciliation va a buscar la verdad cuando el PSP y tu ledger no coinciden.
* **`PaymentSession`** — la sesión PSP-hosted. Cuando usas Drop-in, hosted fields, 3DS challenge o redirect, el PSP te devuelve un `session.id` con TTL. Eso no pertenece al `PaymentIntent` — vive aparte.
* **`PaymentMethod` / `Token`** — el método de pago tokenizado. Nunca guardes PAN/CVV. Guarda el token del PSP + metadata (last4, brand, exp).
* **`WebhookEvent`** — el evento crudo del PSP, persistido **antes** de procesar. Incluye payload, headers, IP, firma verificada y un `UNIQUE(gateway, event_id)` que garantiza dedupe a nivel DB.
* **`IdempotencyRecord`** — el recovery point. No alcanza con un `Idempotency-Key`; necesitas saber **en qué paso del flujo estás** para no repetir el cobro.
* **`GatewayRegistry` + `CapabilityRegistry`** — el catálogo de gateways y qué puede hacer cada uno. El dominio consulta capacidades *antes* de actuar.
* **`OperationResult`** — éxito o fracaso **tipado**. `CardDeclined`, `RequiresAction`, `InsufficientFunds` son **resultados**, no excepciones. Las excepciones quedan para bugs reales.
* **`OutboxEntry`** — el patrón outbox. Garantiza que un evento de dominio se publique exactamente cuando la transacción de DB se commitea, no antes, no después.
> *La diferencia entre un sistema que escala y uno que no es si estas 9 piezas existen como conceptos explícitos o están **dispersas como columnas y banderas en un único modelo gigante**.*
---
## 5. Los 8 flujos canónicos (+ reconcile)
Toda operación que cualquier PSP del mundo te puede ofrecer se reduce a estos **8 flujos**. Si tu sistema tiene 30 "operaciones distintas", lo más probable es que tengas 8 mal mapeadas.
| Flujo | Qué hace |
|---|---|
| `tokenize` | Convertir un método de pago en un token reutilizable |
| `authorize` | Reservar fondos sin cobrar |
| `capture` | Cobrar fondos previamente autorizados |
| `sale` | Authorize + Capture en un solo paso |
| `refund_full` | Devolver el monto completo |
| `refund_partial` | Devolver parte del monto |
| `void` | Cancelar una autorización no capturada |
| `webhook_event` | Procesar un evento asíncrono del PSP |
Más uno extra que rara vez se modela bien:
| Flujo | Qué hace |
|---|---|
| `reconcile` | Cruzar el estado del PSP contra mi ledger |
Cada gateway implementa **solo el subset que su capability registry declara**. Por ejemplo: BAC no soporta `void`, Razorpay no soporta `capture` separado de `sale`. Tu dominio lo sabe vía el `CapabilityRegistry` y no intenta llamar a operaciones inexistentes.
> *Si tu equipo está debatiendo "¿esto es un capture o un sale?", es señal de que el modelo está bien — porque la pregunta tiene una sola respuesta correcta. Si están debatiendo "¿esto es un `processPayment_v2_for_BAC` o un `processPayment_alternate`?", es señal de que el modelo no existe.*
---
## 6. Capability Registry — el cerebro detrás del multi-gateway
Esta es la pieza que más subestiman los equipos. El `CapabilityRegistry` es donde declaro **qué puede hacer cada gateway**:
```yaml
stripe:
hosted_fields: true
3ds: true
auth_capture: true
one_step_sale: true
refund_partial: true
void: true
card_on_file: true
recurring: true
webhook: true
adyen:
hosted_fields: true
3ds: true
auth_capture: true
refund_partial: true
void: true
card_on_file: true
webhook: true
bac:
direct_pan: true
one_step_sale: true
refund_full: true
refund_partial: false
void: false
webhook: false
```
¿Por qué importa tanto?
Porque el dominio puede preguntar antes de actuar:
```ruby
if registry.supports?(gateway, :void)
adapter_for(gateway).void(intent)
else
adapter_for(gateway).refund_full(intent)
end
```
Sin esto, terminas con `if gateway == 'bac'` regados por todo el código. Con esto, **agregar un gateway nuevo es declarar sus capacidades y escribir su adapter — no tocar 15 archivos**.
Es también lo que el frontend consulta vía API: *"para este facility, con este método de pago, ¿qué puedo ofrecer al usuario?"*. La UI se vuelve dinámica sin acoplarse a gateways específicos.
---
# Parte III — Patrones de diseño que uso siempre
## 7. Patrones de diseño aplicados a payments
Voy a ser concreto: estos son los **patrones que efectivamente uso** en sistemas de pagos, no una lista académica de GoF. Cada uno resuelve un problema específico.
### 7.1 Adapter
Un contrato uniforme (`GatewayAdapter`), N implementaciones (`StripeAdapter`, `AdyenAdapter`…). Cada adapter expone los flujos canónicos que su gateway soporta. La inspiración clara es **ActiveMerchant** del mundo Ruby.
### 7.2 Strategy
Selección dinámica del gateway según contexto: país, moneda, método de pago, monto, hora del día. El Strategy vive en una capa por encima de los adapters y decide *cuál* usar.
### 7.3 Registry
Lookup por nombre + metadata. El `GatewayRegistry` resuelve `"stripe"` → `StripeAdapter`. El `CapabilityRegistry` resuelve `("stripe", :3ds)` → `true`.
### 7.4 Factory
Construye adapters con sus dependencias inyectadas (credenciales del facility, logger, HTTP client). Centraliza la creación.
### 7.5 Chain of Responsibility
Un pipeline de validaciones antes de llamar al PSP: ¿tenemos credenciales? ¿el monto es válido? ¿el método de pago tiene los permisos? ¿hay anti-fraude que aprobar? Cada handler decide si continúa o aborta.
### 7.6 Saga / Process Manager
Para flujos largos: authorize → esperar 3DS → confirm → capture. **No uso transacciones distribuidas** entre mi DB y el PSP — es imposible. Modelo cada paso como una etapa de saga con su propio commit local + idempotency.
### 7.7 Outbox Pattern
El más subestimado de todos. Cuando creo un `PaymentIntent`, escribo en la misma transacción de DB:
1. El `PaymentIntent` con estado `authorized`.
2. Una fila en `outbox_entries` con el evento `PaymentAuthorized`.
Un worker independiente lee la outbox y publica al bus (Kafka, RabbitMQ, Pub/Sub). **Garantía exactly-once a costa de potencialmente entregar duplicados — pero nunca de perder eventos**.
### 7.8 Circuit Breaker
Cuando un PSP está caído, no quiero seguir mandándole requests. El circuit breaker abre el circuito tras N fallos consecutivos, deja pasar requests de prueba después de un cooldown, y se recupera solo. Sin esto, una caída del PSP **te tumba a ti**.
### 7.9 Bulkhead
Separo los workers / threads / colas por gateway. Si Xendit está lento y satura su pool, **Stripe sigue funcionando**. Sin bulkheading, un PSP lento contamina a todos los demás.
---
## 8. Idempotencia — la disciplina que evita el doble cobro
Si tuviera que elegir **un único concepto** que define la madurez de un sistema de pagos, sería este. Y casi nadie lo hace bien.
Lo que la mayoría hace: mandar un `Idempotency-Key` al PSP. Está bien, pero **no es suficiente**.
Lo que hace Brandur en su famoso post sobre Rocket Rides (te lo recomiendo si no lo has leído): cada operación de pago es una secuencia de pasos, y cada paso es un **recovery point**. Si crasheo en el paso 3, al reintentar arranco desde el paso 3 — no desde cero.
Pseudo-flujo:
```
1. CreatePaymentIntent → recovery_point = 'intent_created'
2. CallGatewayAuthorize → recovery_point = 'authorized'
3. PersistTransactionLog → recovery_point = 'logged'
4. PublishEvent → recovery_point = 'published'
5. Done → recovery_point = 'done'
```
Si crasheo entre 2 y 3, el reintento ve `authorized` y **no vuelve a llamar al PSP**. Solo persiste el log y publica el evento.
**La regla de oro:** nunca llamar al PSP dentro de una transacción de DB. La secuencia es:
1. Persistir el intento + idempotency key (commit).
2. Llamar al PSP (sin transacción abierta).
3. Persistir el resultado + actualizar recovery point (commit).
El escenario más peligroso es el **timeout del PSP**. Si el PSP no responde, **no sabes si cobró o no**. La única salida segura: dedicar el siguiente reintento a **consultar el estado** (no a reintentar el cobro). Aquí es donde el `Idempotency-Key` te salva — al consultar, el PSP devuelve el resultado de la primera llamada.
Idempotency vive a **tres niveles**: en el cliente (no doble click), en tu API (no doble request del cliente), y en el adapter (no doble llamada al PSP).
---
# Parte IV — Comunicación con el mundo exterior
## 9. Webhooks — la pieza más subestimada
Los webhooks son donde más he visto perder pagos. Tres reglas innegociables:
### 9.1 Persistir el payload crudo ANTES de procesar
La secuencia que uso:
1. Recibo el HTTP request del PSP.
2. Verifico firma (timing-safe — `==` no sirve, leak de side-channel).
3. Persisto `WebhookEvent` con raw payload, headers, IP, `signature_verified`, y un `UNIQUE(gateway, event_id)`.
4. Encolo job de procesamiento.
5. Respondo `200 OK` al PSP.
6. El worker procesa el evento desde la tabla, **no desde el request HTTP**.
¿Por qué? Si el worker crashea, el evento sigue en la DB. Si el PSP reenvía, el `UNIQUE` lo deduplica. Si necesito debuggear, el raw payload está ahí.
### 9.2 Responder 200 OK antes de procesar
Muchos PSPs reintentan agresivamente si tardas más de 5 segundos. **No proceses el evento de forma síncrona**. Persiste, encola, responde 200, y procesa async. Si después falla, lo retomas — ya tienes el raw.
### 9.3 Orden de eventos
Los webhooks **no llegan en orden**. Puedes recibir `payment.refunded` antes que `payment.captured` por race conditions del PSP. Tu state machine debe ser tolerante: si llega `refunded` y el intent está en `authorized`, lo dejas en una cola de "pendiente de reordenar" y reintenta cuando llegue `captured`.
> *Y por favor: nunca confíes en que el webhook es la única señal. Es **una** señal. La verdad la define reconciliation.*
---
## 10. Sockets y comunicación en tiempo real
Aquí entran flujos que muchos olvidan diseñar. Cuando un pago es **asíncrono** (Xendit, 3DS con redirect, Pix con QR), el usuario está mirando una pantalla esperando el resultado. ¿Cómo le aviso cuándo termina?
### 10.1 WebSockets
Conexión bidireccional persistente. Útil cuando necesitas push del backend al cliente. El patrón típico:
1. El cliente abre socket y se subscribe a `payment_intent.{id}`.
2. Backend recibe webhook → procesa → publica evento interno.
3. Un listener escucha el evento y emite por el socket al cliente subscrito.
4. El cliente recibe el evento y actualiza la UI.
### 10.2 Server-Sent Events (SSE)
Más simple que WebSocket si solo necesitas comunicación **del backend al cliente**. HTTP plano, reconnect automático, fácil de operar. Lo uso cuando el flujo es solo "esperar resultado de pago" y no requiere bidirección.
### 10.3 Long polling
Cuando WebSocket no es viable (corporate proxies, ambientes legacy). El cliente hace request, el backend lo retiene hasta tener resultado o timeout, y responde. El cliente repite. Sirve, pero escala peor.
### 10.4 Push via PubSub provider (Pusher, Ably, Pub/Sub)
Para mobile + multi-cliente. El cliente se subscribe a un canal y el backend publica al canal. Manejas menos infraestructura propia.
### Tabla comparativa rápida
| Mecanismo | Bidireccional | Operativamente | Cuándo lo uso |
|---|---|---|---|
| WebSocket | Sí | Complejo (sticky sessions, scale-out) | Apps con muchas interacciones realtime |
| SSE | No (solo server→client) | Simple | Notificación de resultado de pago |
| Long polling | No | Sencillo, mal performance | Ambientes con restricciones de red |
| PubSub provider | Sí | Tercerizado | Mobile + multi-device |
---
## 11. Listeners y arquitectura event-driven
Cuando un pago se autoriza, suelen pasar **muchas cosas**: enviar email, actualizar inventario, notificar al CRM, gatillar workflows de loyalty, escribir al data warehouse. Si lo haces todo síncrono en el use case, el código se vuelve un monstruo.
La solución es publicar **eventos de dominio** y dejar que listeners reaccionen.
### 11.1 Domain events vs Integration events
Esta diferencia casi nadie la respeta y es crítica:
* **Domain events** — internos a tu sistema. Ejemplo: `PaymentAuthorized`. Los publicas en proceso o en un bus interno. Los consume tu propio código.
* **Integration events** — para sistemas externos. Ejemplo: `customer.charge.completed`. Los publicas a Kafka/Pub/Sub. Los consume otro servicio o equipo.
Mezclarlos es un error: cambias un domain event interno y rompes un consumidor externo del que no sabías.
### 11.2 Listeners idempotentes
Los eventos se **reentregan**. Tu listener debe ser idempotente. Si recibe el mismo evento dos veces, no manda dos emails, no carga dos veces el saldo. Esto se logra con un `processed_events` table o con un check explícito antes de actuar.
### 11.3 Event sourcing parcial
No hago event sourcing completo en payments (es overkill y complica la consistencia financiera), pero sí uso `PaymentTransaction` **como log de eventos**: una fila append-only por cada acción significativa. El estado del `PaymentIntent` se deriva del último estado válido, pero la historia está intacta.
### 11.4 Cómo evito que se vuelva un caos
- **Registro explícito** de listeners. Nada de auto-discovery mágico.
- **Naming convention**: `On` (e.g. `OnPaymentAuthorized::SendReceiptEmail`).
- **Un listener por archivo**, un test por listener.
- **Lista única** de eventos del dominio, documentada como contrato.
---
## 12. Polling — cuando no queda otra
Algunos PSPs (especialmente en mercados emergentes) **no envían webhooks confiables** o los envían con horas de retraso. Para estos casos, polling es la salida pragmática.
Estrategia:
1. Crear el intent.
2. Encolar un job que consulta el estado del PSP.
3. Si no hay resolución, reencolar con **backoff exponencial** (1s, 5s, 30s, 2min, 10min…).
4. Cortar a un timeout sensato (24h o lo que dicte el PSP).
5. Si pasa el timeout sin resolución, el intent va a `expired` y reconciliation lo detecta.
Polling **no reemplaza** webhooks ni reconciliation. Es una tercera señal. Las tres se complementan.
---
# Parte V — Estrategias operativas y de resiliencia
## 13. Retry, failover y backoff
Aquí distingo cuatro estrategias que **no son intercambiables**:
| Estrategia | Cuándo aplica | Riesgo |
|---|---|---|
| **Retry inmediato** | Timeout puro, network blip | Muy bajo |
| **Retry con backoff** | 5xx del PSP, rate limit | Bajo |
| **Failover a otro gateway** | PSP completamente caído | **Alto** — riesgo de doble cobro |
| **No retry** | 4xx del usuario (CardDeclined, InsufficientFunds) | N/A — sería gastar fees |
**Backoff exponencial con jitter.** Sin jitter, todos tus workers reintentan al mismo tiempo y golpean al PSP justo cuando empieza a recuperarse. El jitter (variación aleatoria) los espacia.
**Failover entre gateways** es la estrategia más peligrosa. Si el PSP A ya cobró pero respondió con timeout, y haces failover a B, **acabas de cobrar dos veces**. Solo es seguro si:
- A definitivamente no cobró (respuesta explícita de error sin transacción persistida).
- O tienes un mecanismo posterior de reconciliation y refund automático.
**Dead Letter Queue (DLQ).** Todo lo que no se resuelve tras N reintentos va a la DLQ. Una persona revisa diariamente. Sin esto, los pagos fallidos se acumulan en silencio.
---
## 14. Selección dinámica de gateway (routing)
Routing es decidir, en tiempo real, **a qué PSP mando este pago**. Las estrategias que uso:
* **Routing por geografía/moneda** — pagos en BRL van a un PSP local; pagos en EUR van a Adyen.
* **Least-cost routing** — entre los PSPs habilitados, elijo el más barato para ese tipo de transacción.
* **Capability-based routing** — si necesito 3DS y el PSP A no lo soporta, voy al B.
* **A/B routing** — el 10% del tráfico va a un PSP nuevo para validarlo en producción.
* **Health-check routing** — si el circuit breaker de un PSP está abierto, lo excluyo automáticamente.
El routing debe ser **observable**: tengo que saber, para cada pago, *por qué* eligió el gateway que eligió. Un log estructurado con `routing_reason` me ha salvado de varios incidentes.
---
## 15. Reconciliation — la verdad cruzada
Reconciliation es la **red de seguridad** del sistema entero. Es lo que detecta cuándo tu ledger y el PSP no coinciden. Y casi siempre va a coincidir 99% — pero ese 1% es donde está el dinero perdido.
La idea es simple: descargar diariamente el extracto del PSP (settlements, payouts) y compararlo contra tu `PaymentTransaction` log. Tres outcomes posibles:
1. **Coinciden** → todo bien, marca como reconciliado.
2. **El PSP cobró pero no tienes registro** → ghost charge. Investiga.
3. **Tienes registro pero el PSP no cobró** → fantasma local. Posiblemente intent abandonado.
Mi recomendación cuando arrancas con un sistema legacy: **la primera capacidad de la nueva arquitectura que entregas a producción es reconciliation read-only**. ¿Por qué?
* Blast radius cero — no escribe nada.
* Valor inmediato a Finance Ops.
* Te enseña cómo es el modelo real de eventos del PSP sin riesgo.
* Te da una base de verdad para todo lo que viene después.
Schema gateway-agnostic + adapter por PSP. Agregar el segundo gateway a reconciliation es escribir un adapter, no migrar un schema.
---
## 16. Observabilidad — logs, métricas, traces, alertas
En payments, *"no sé qué pasó con ese pago"* no es una respuesta aceptable. La observabilidad mínima:
* **Logs estructurados con `correlation_id`** — todo lo que tocó ese pago (controller → use case → adapter → webhook → listener) comparte el mismo ID. Trazar un pago de punta a punta es un solo query.
* **Métricas críticas por gateway**:
- Success rate (target > 95%).
- Latencia P95/P99 (alerta si crece 50%).
- Retry rate (si sube, algo está mal).
- Webhook lag (tiempo entre evento del PSP y procesamiento).
* **Distributed tracing** (OpenTelemetry, Datadog APM) — sigue un pago desde el click del usuario hasta el settlement bancario.
* **Alertas con criterio.** Alarmar por *success rate < 90% sostenido 5 min* sí. Alarmar por *un pago falló* no. Aprende a calibrar; alertas mal calibradas matan equipos.
* **Dashboard por gateway + dashboard global.** Cuando algo se rompe, el primer instinto es *"¿es uno o son todos?"*.
---
# Parte VI — Seguridad y compliance
## 17. PCI, tokenización y vault
PCI-DSS es el marco regulatorio de tarjetas. Determina **qué tan auditado** tiene que estar tu sistema. La diferencia entre **SAQ A** (mínimo) y **SAQ D** (máximo) son cientos de miles de dólares al año en compliance.
La regla que sigo: **nunca toco PAN/CVV en mi infraestructura**. Uso:
* **Hosted fields / iframes del PSP** — el usuario teclea la tarjeta dentro de un iframe del PSP. Tú nunca ves los datos.
* **Drop-in UI** — el PSP te da un componente UI completo. Aún más simple.
* **Tokenización en el cliente** — SDK del PSP convierte la tarjeta en un token *antes* de tocar tu servidor.
¿Vault propio? **Casi nunca vale la pena**. El costo de mantener PCI SAQ D supera por mucho el ahorro en fees. Excepción: si tu negocio es procesar pagos a escala masiva y los fees del vault del PSP son prohibitivos.
**Network tokens** son el futuro cercano. En vez de tokens propietarios del PSP, las redes (Visa, Mastercard) emiten tokens que sobreviven a re-emisiones de tarjeta. Tu rate de aprobación sube.
**3DS / SCA** — necesario en Europa por PSD2, opcional en otras regiones. Mi recomendación: integralo desde el inicio aunque tu mercado no lo exija — luego no quieres retrofittearlo.
---
## 18. Seguridad operativa
Más allá de PCI, hay capas de seguridad operativa que muchos olvidan:
* **Rate limiting** — por IP, por user, por método de pago. Sin esto, eres víctima fácil de **card-testing attacks** (bots probando tarjetas robadas en tu sistema).
* **Card-testing detection** — patrones como muchos rechazos seguidos desde la misma IP, montos chiquitos consecutivos, tarjetas con BIN sospechoso. Modelo simple → alerta → bloqueo temporal.
* **Honeypots** — endpoints decoy, campos anti-bot en formularios, partial fake credentials. Detectan probing sin alertar al atacante. Es seguridad **observability low-interaction** — no bloqueas, observas.
* **Rotación de credenciales del PSP** — calendarizada, automatizada, sin downtime. Si un secret leakea, debe ser cambiable en minutos.
* **Auditoría de accesos** — quién consulta qué método de pago de qué usuario. Log inmutable.
---
# Parte VII — Frontend en sistemas multi-gateway
## 19. Cómo no acoplar tu UI al gateway
El frontend es donde más he visto sistemas multi-gateway colapsar. El típico patrón malo: `if (gateway === 'stripe') { ... } else if (gateway === 'adyen') { ... }` por todas partes.
Lo que hago en su lugar:
### 19.1 Plugin pattern
La UI emite **eventos canónicos**, no eventos por gateway. Los eventos son del estilo `payment:requires_action`, `payment:authorized`, `payment:failed`. El plugin (que internamente sí conoce al gateway) traduce los eventos del SDK del PSP a este vocabulario común.
El resto del frontend escucha **solo** los eventos canónicos. Agregar un gateway nuevo = escribir un plugin nuevo. No tocar el resto.
### 19.2 Hosted fields / iframes del PSP
Reducen el PCI scope a casi nada. Trade-off: pierdes algo de control de UX. En 9 de cada 10 casos vale la pena.
### 19.3 Capability-driven UI
El frontend consulta a la API: *"para este facility + método + monto, ¿qué puedo ofrecer?"*. El backend responde con las capacidades aplicables. La UI se renderiza dinámicamente.
Resultado: si mañana un facility cambia de gateway, la UI se adapta sola — sin redeploy del frontend.
### 19.4 Mobile
- Deep links para volver a la app tras un 3DS web.
- SDK nativo del PSP cuando exista (mejor UX).
- Fallback a web view cuando no.
- Mismo vocabulario canónico de eventos que el web.
---
# Parte VIII — Testing, despliegue y migración
## 20. Testing en sistemas de pagos
No puedes confiar en tests manuales. Lo que uso:
* **Contract testing** — el adapter cumple el contrato del `GatewayAdapter`. Sin esto, alguien rompe la interfaz y nadie se da cuenta hasta producción.
* **Fake gateways** (`BogusGateway` à la ActiveMerchant) — adapter en memoria con escenarios programables: `decline`, `requires_action`, `timeout`, `network_error`. Permite testear flujos completos sin tocar al PSP real.
* **Sandbox del PSP** — para tests de integración nightly. Lentos pero realistas.
* **Webhook replay tests** — alimento el sistema con secuencias grabadas de webhooks reales (en orden y desorden) y verifico que el state machine se comporta bien.
* **Chaos / load tests** — antes de meter un PSP nuevo a producción: ¿qué pasa con 1000 webhooks/segundo? ¿qué pasa si el PSP devuelve timeouts el 20% del tiempo?
---
## 21. Estrategias de despliegue
* **Feature flags por gateway + por facility** — habilito el gateway nuevo para 1 cliente, luego para 10, luego para 100. Si algo falla, revierto el flag.
* **Canary deployments** — un % chico del tráfico va a la versión nueva. Observo métricas. Promuevo si todo está bien.
* **Shadow mode** — el gateway nuevo procesa **en paralelo** al actual pero **no commitea**. Comparo los resultados. Valido sin riesgo financiero.
* **Strangler-fig** — para sistemas legacy. Lo cubro en la siguiente sección.
---
## 22. Migración: cuando ya tienes un sistema legacy hecho un desastre
Si llegaste a este post con un sistema legacy que ya tiene 5 anti-patrones encima, no te desesperes. Yo he migrado varios. La estrategia que funciona:
### 22.1 No hagas un rewrite
Los rewrites de sistemas de pagos **fracasan el 90% del tiempo**. Demasiada lógica de negocio invisible, demasiados edge cases que solo viven en producción. No vas a poder pararlos durante 6 meses para reescribir.
### 22.2 Strangler-fig + nuevo gateway como piloto
La estrategia que me ha funcionado: introducir la nueva arquitectura **junto con un gateway nuevo** (greenfield). El gateway nuevo vive 100% en el nuevo modelo. El legacy queda intacto.
¿Por qué con uno nuevo? Porque no carga deuda histórica, no rompe paridad con clientes existentes, y te deja validar el diseño sin riesgo de regresión.
### 22.3 Reconciliation-first
La primera capacidad de la nueva arquitectura que entregas a producción es **reconciliation read-only sobre el legacy**. Cero blast radius, valor inmediato, te enseña el modelo real.
### 22.4 Coexistencia larga
El legacy y la nueva arquitectura van a convivir **meses o años**. Acéptalo desde el principio. Diseña los namespaces y las abstracciones pensando en convivencia, no en switch.
### 22.5 Retira el legacy cuando ya no quede nada
El último gateway legacy se migra cuando hay justificación de negocio (cambio de pricing, nueva capability requerida). No por estética arquitectónica.
---
# Parte IX — Lo que NO debes hacer
## 23. Errores que cometí o vi cometer
Cierro con la lista anti-pattern definitiva. Si no haces nada de lo anterior pero al menos evitas esto, ya estás mejor que la mayoría:
* ❌ **Dual-write entre dos ledgers.** Mantener dos `Payment`-equivalentes sincronizados durante meses introduce más bugs financieros de los que arregla.
* ❌ **Migrar todos los gateways al mismo tiempo.** Strangler-fig siempre. Uno por uno.
* ❌ **Esconder los gateways detrás de una gem/lib "mágica"** que abstrae todo. Pierdes control de los flows reales, depuras a ciegas, y la magia se rompe cuando un PSP introduce un edge case nuevo.
* ❌ **Tratar a los webhooks como source of truth.** Son notificaciones. La verdad la define reconciliation cruzando contra el ledger del PSP.
* ❌ **Hacer failover automático entre gateways sin idempotency garantizada.** Riesgo de doble cobro real.
* ❌ **Mantener tarjetas en tu propia DB.** El costo de PCI SAQ D es brutal. Casi nunca compensa.
* ❌ **Acoplar tu modelo financiero al modelo del PSP.** Tu `PaymentIntent` no debería tener un campo `stripe_payment_intent_id`. Debería tener un `gateway` + `external_id` agnóstico.
* ❌ **No persistir el raw payload de los webhooks.** Cuando algo falle en producción (y va a fallar), sin el raw payload estás a ciegas.
* ❌ **Reintentar todo, incluidos los 4xx.** `CardDeclined` no se reintenta. `InsufficientFunds` no se reintenta. Cada reintento es un fee gastado.
* ❌ **No tener observabilidad por gateway.** Cuando tu success rate global cae al 80%, necesitas saber **cuál PSP** es el culpable en segundos, no en horas.
---
## Conclusión: la arquitectura no se hace en PowerPoint, se construye iterando
Lo que leíste no es teoría. Es la suma de cicatrices de varios proyectos donde aprendí lo que NO funciona — a veces a costa de incidentes en producción, otras veces refactorizando código heredado que ya nadie entendía.
Si arrancas hoy un sistema de pagos multi-gateway, este esqueleto te va a evitar dolor en dos años:
1. **Separa las 6 capas** desde el día uno.
2. **Modela las 9 abstracciones core** explícitamente — no como columnas en un modelo gigante.
3. **Usa los 8 flujos canónicos** + reconcile como vocabulario único.
4. **Capability registry** como cerebro del multi-gateway.
5. **Adapters con contrato uniforme**, errores normalizados en el borde.
6. **Idempotencia con recovery points**, no solo con `Idempotency-Key`.
7. **Webhooks → persistir antes de procesar**, dedupe en DB.
8. **Sockets / SSE** para feedback realtime al usuario.
9. **Listeners idempotentes** para mantener el código de los use cases limpio.
10. **Reconciliation read-only** como red de seguridad.
11. **Observabilidad y métricas por gateway**.
12. **PCI scope mínimo** — hosted fields, jamás vault propio salvo excepción.
Si llegaste tarde y ya tienes un sistema legacy, el camino es: **strangler-fig + nuevo gateway como piloto + reconciliation-first**. No rewrite. No big-bang. Coexistencia larga, migración incremental.
Ningún sistema de pagos sobrevive sin disciplina arquitectónica. Y la disciplina arquitectónica se construye **antes** de necesitarla, no después.
> *El día que un PSP global se cae durante 4 horas, y tu sistema sigue funcionando porque routeó al backup automático, es el día que entiendes por qué valió la pena cada hora invertida en este esqueleto.*
---
*En el próximo post de esta serie hablaremos de cómo comunicar arquitectura de payments a stakeholders no técnicos — el arte de pasar de diagramas a decisiones de negocio.*